
10、微调-2
什么是训练/预训练/微调/轻量化微调
- 模型训练(Training)
- 预训练(Pre-Training)
- 微调(Fine-Tuning)
- 轻量化微调(Parameter Efficient Fine-Tuning, PEFT)
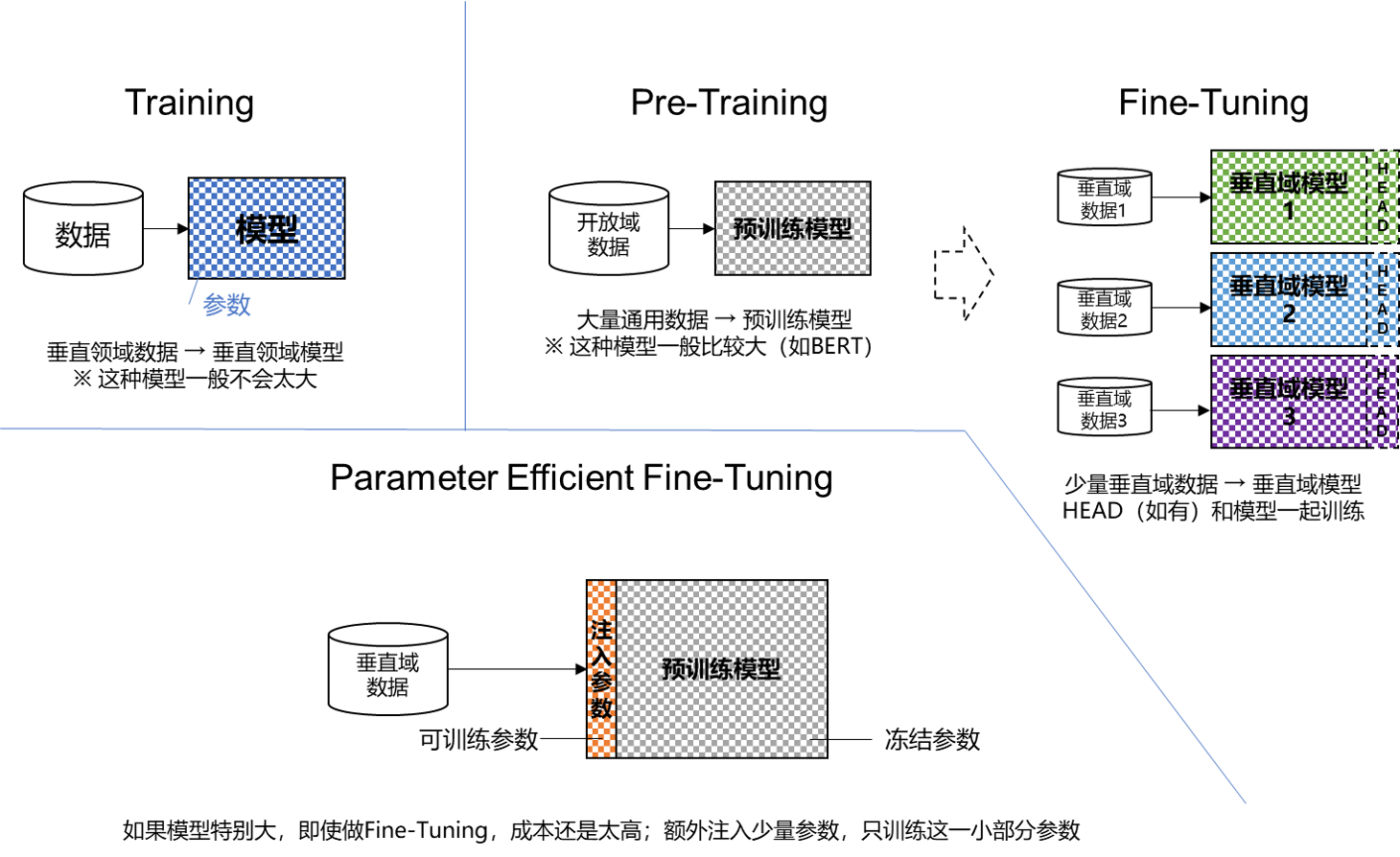
回忆上节课的实验
- MNIST 手写体识别实验,就是 Training
- 电影评论情感分类实验,就是 Fine-Tuning
Pretraing 代码参考
- 不大的模型:以 GPT-2 模型为例
- 第一步:训练 Tokenizer,代码参考:pretraining/train_tokenizer.py
- 第二步:预训练模型,代码参考:pretraining/pretrain_gpt2.py
- 训练条件:8 X A100 40GB GPUs,训练时间 >1 周
- 更快的实现:karpathy/llm.c
- 大语言模型:OLMo
- 开源了预训练一个 LLM 的完整过程和数据集
Transformer 结构简介
Transformer 是组成 LLM 的基本单元。
或者说,一个 LLM 就是一个 $N$ 层 Transformer 网络,例如 GPT-3.5 是 96 层。
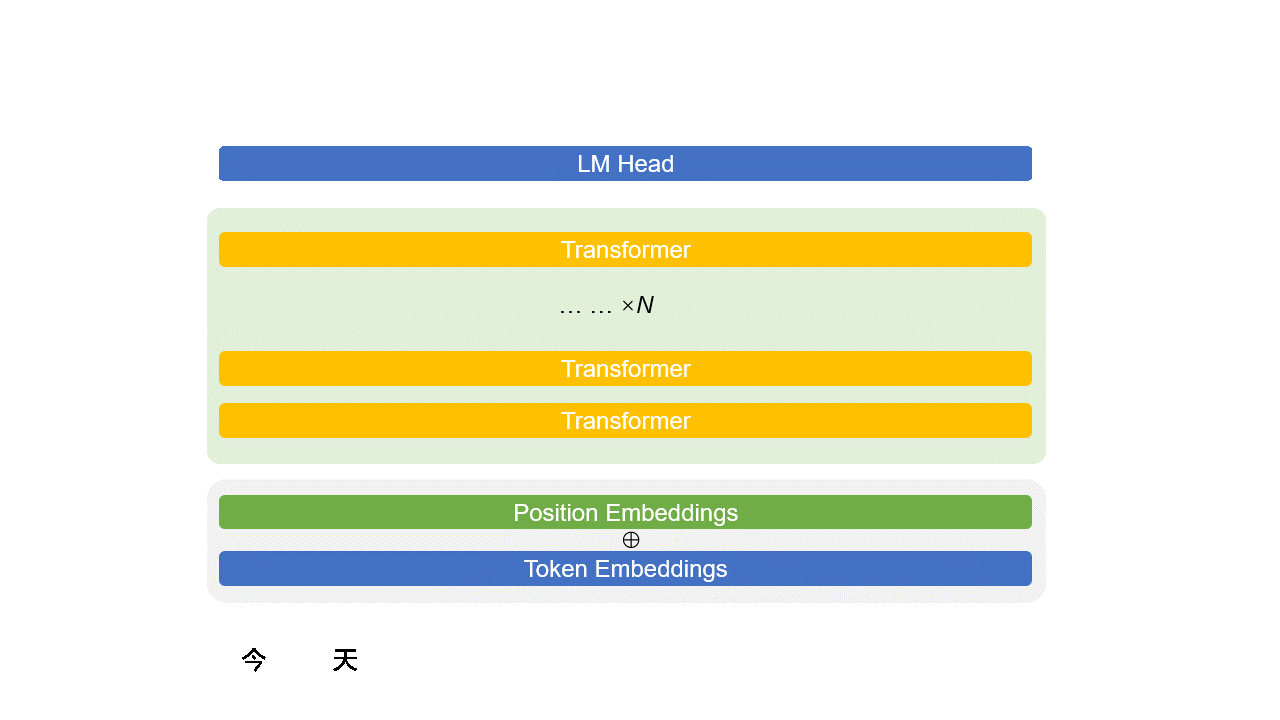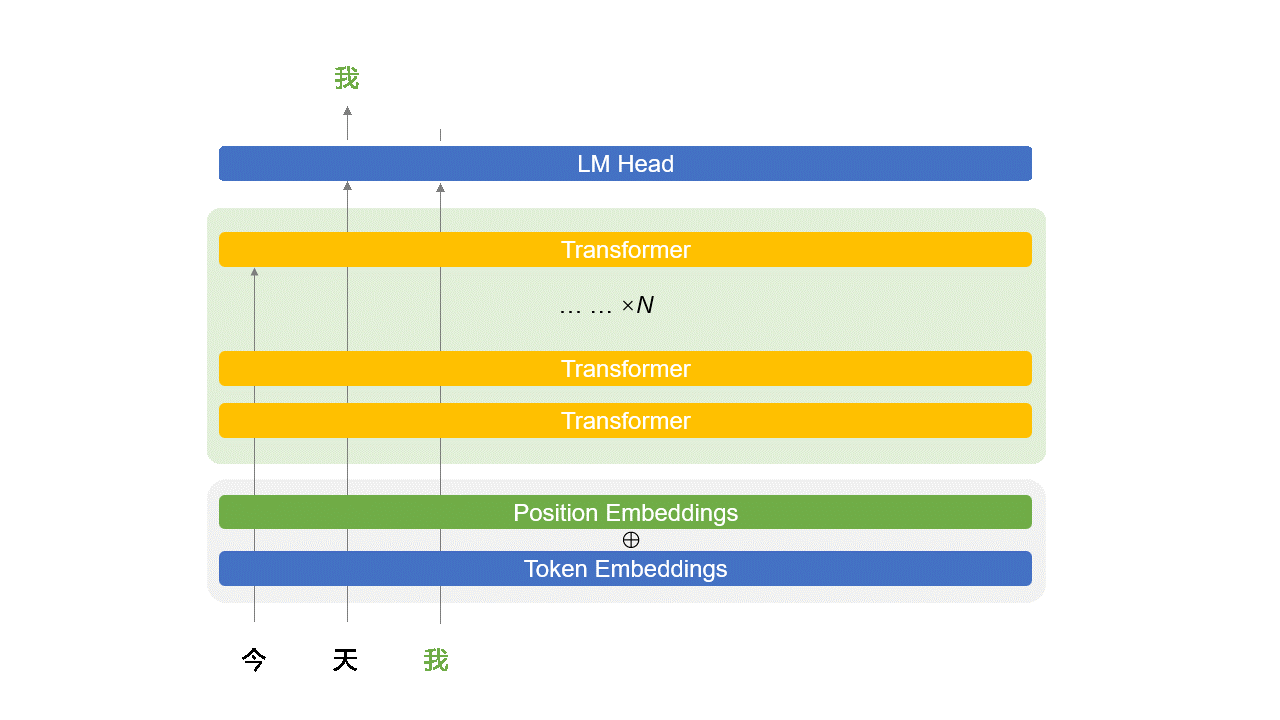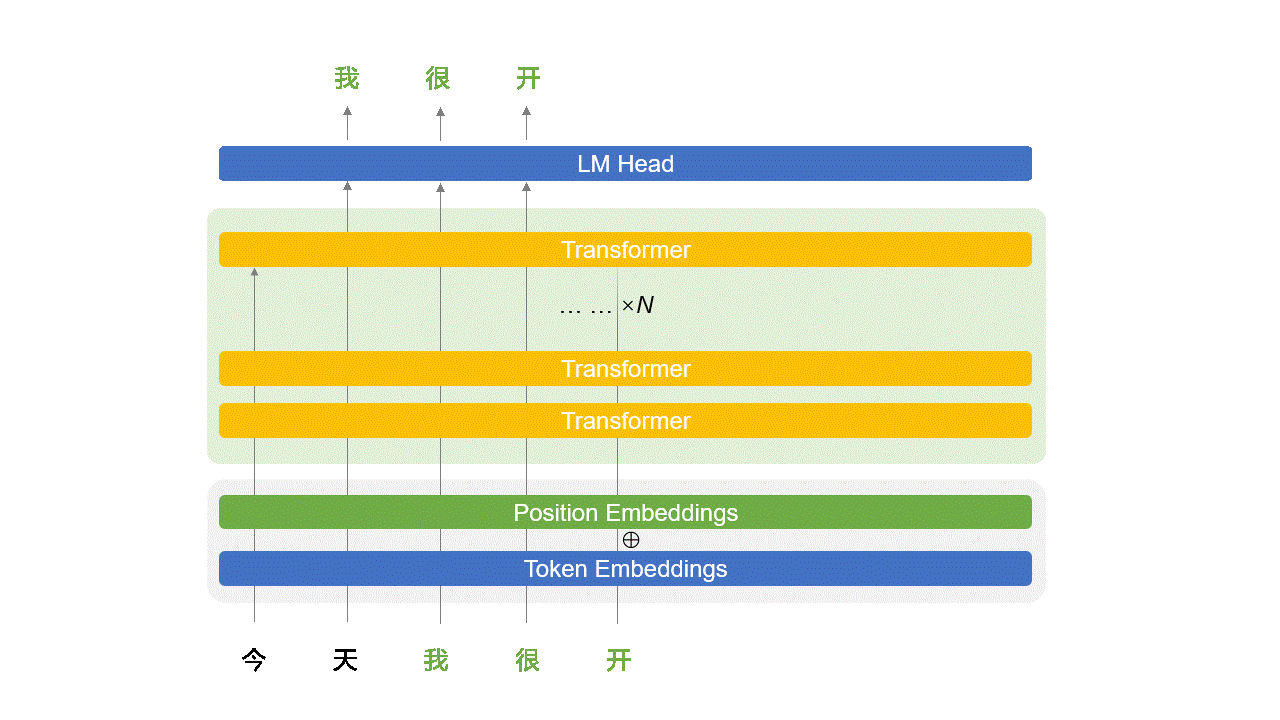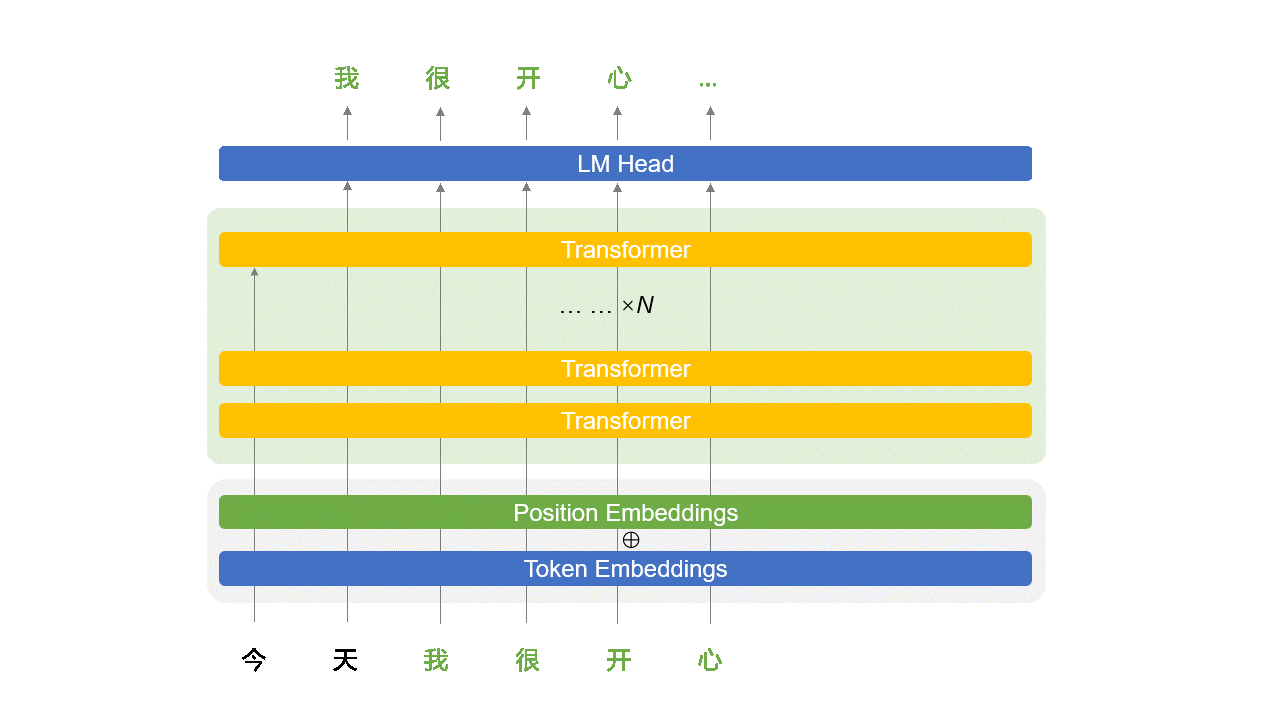
9.1、Transformer 内部解构简图
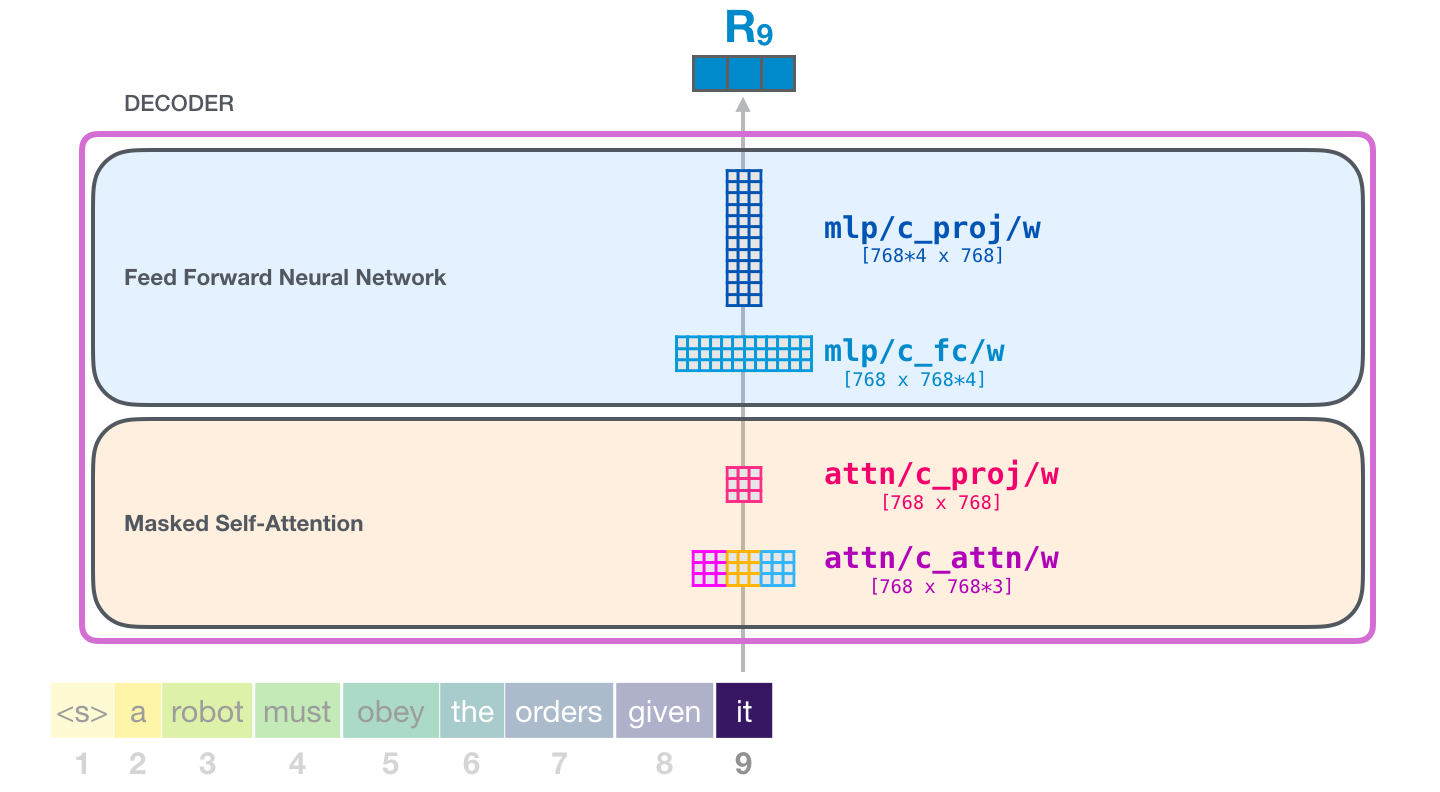
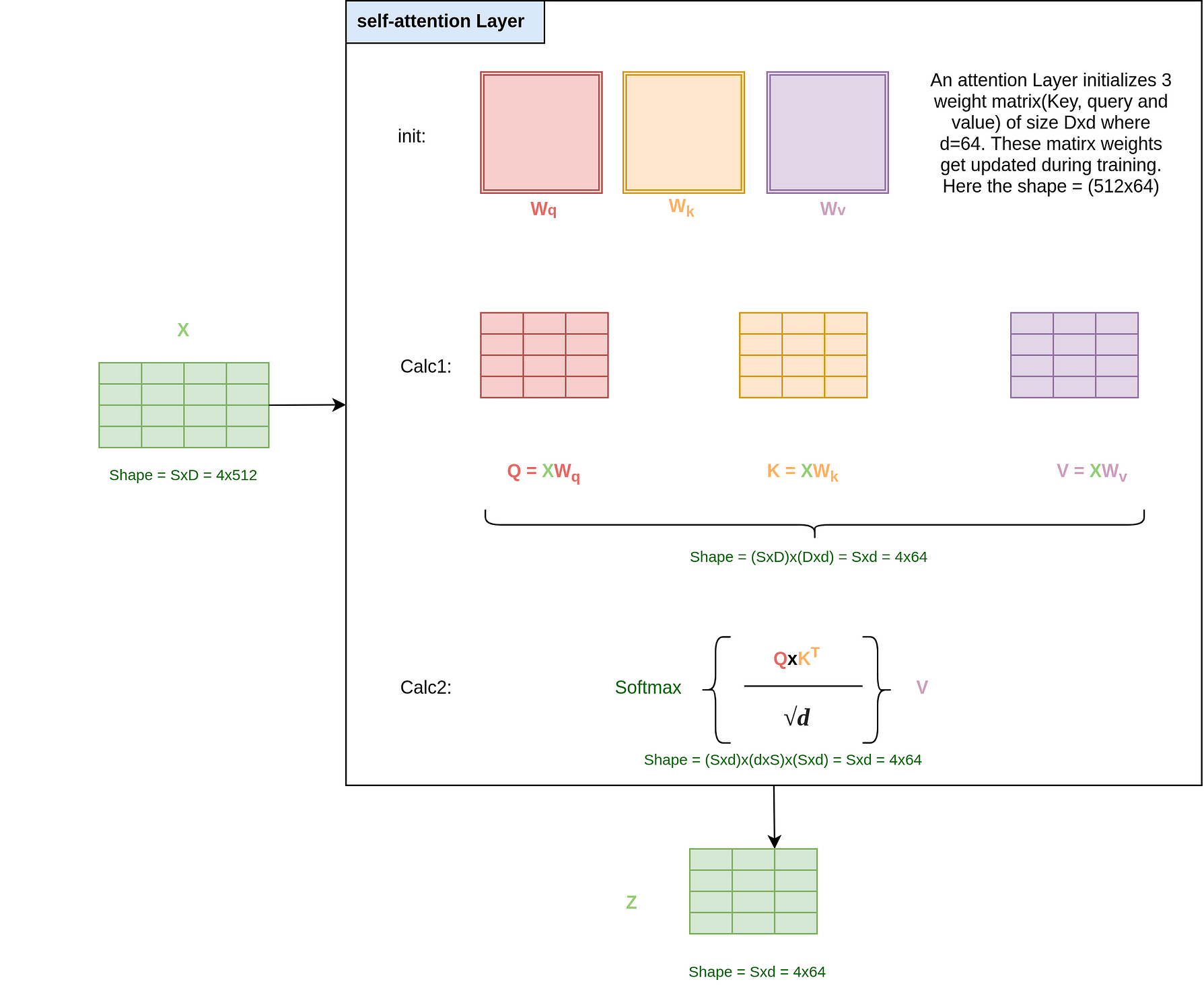
Self-Attention 的计算
全连接层:
- 回忆上节课的全连接网络
- 这里的激活函数一般是 GELU 或 Swish
为了严谨:在 Self-Attention 和全连接网络之间还有个残差和 LayerNorm,图中未展示
9.2、LM Head (选)
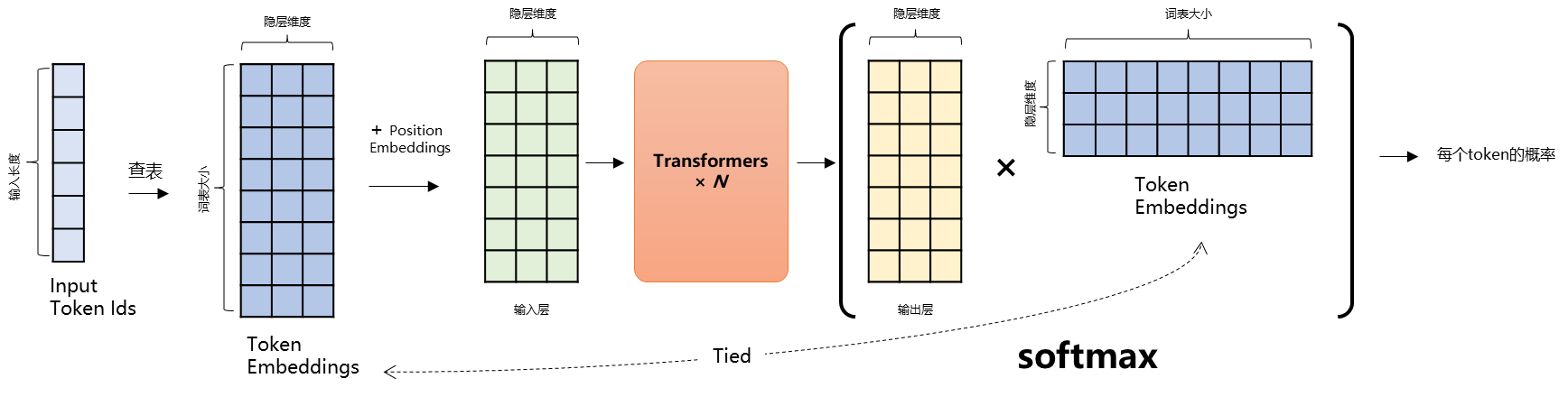
- 更详细的Transformer网络拆解(Encoder-Decoder):https://jalammar.github.io/illustrated-transformer/
- 更详细的GPT模型拆解:https://jalammar.github.io/illustrated-gpt2/
轻量化微调

- 定义微调数据集加载器
- 定义数据处理函数
- 加载预训练模型:AutoModel.from_pretrained(MODEL_NAME_OR_PATH)
- 在预训练模型上增加任务相关输出层 (如果需要)
- 加载预训练 Tokenizer:AutoTokenizer.from_pretrained(MODEL_NAME_OR_PATH)
- 定义注入参数的方法(见下文)
- 定义各种超参
- 定义 Trainer
- 定义 Evaluation Metric
- 开始训练
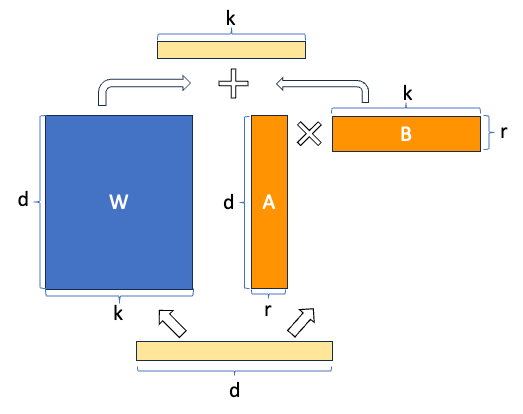
10.1. LoRA
- 在 Transformer 的参数矩阵上加一个低秩矩阵($A\times B$)
- 只训练 A,B
- 理论上可以把上述方法应用于 Transformer 中的任意参数矩阵,包括 Embedding 矩阵
- 通常应用于 Query, Value 两个参数矩阵
10.2. QLoRA
什么是模型量化
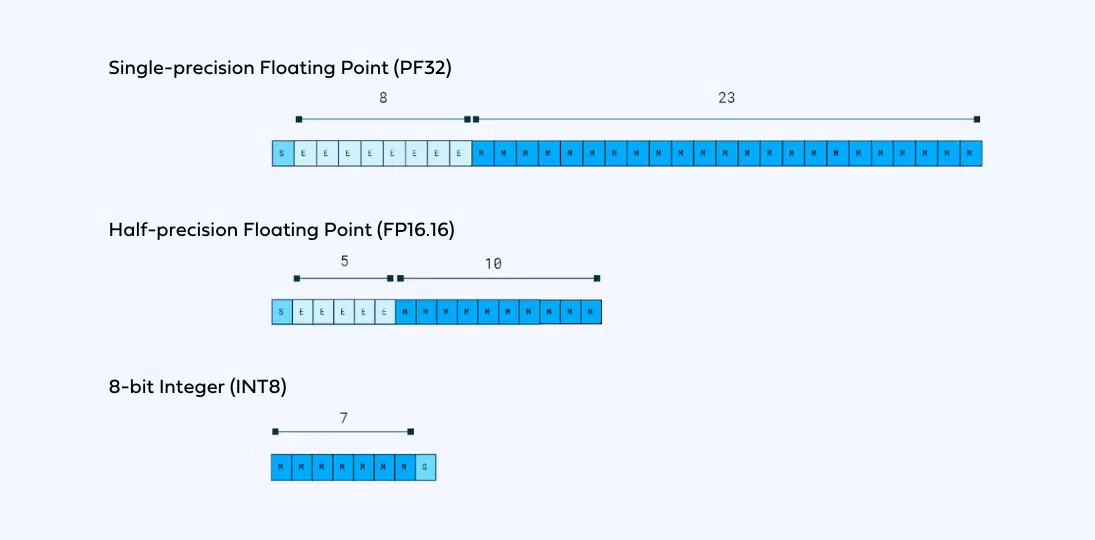
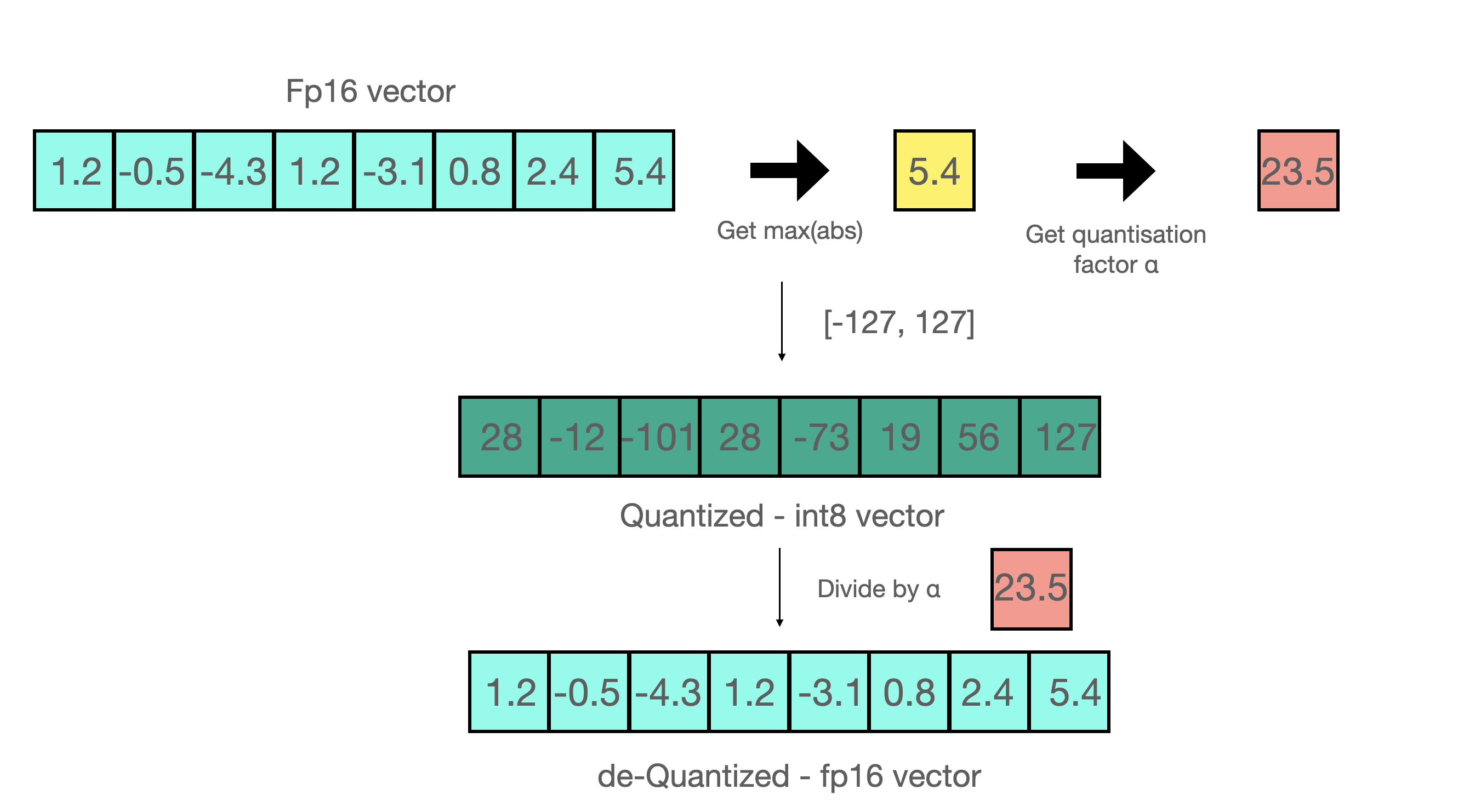
更多参考: https://huggingface.co/blog/hf-bitsandbytes-integration
QLoRA 引入了许多创新来在不牺牲性能的情况下节省显存:
- 4 位 NormalFloat(NF4),一种对于正态分布权重而言信息理论上最优的新数据类型
- 双重量化,通过量化量化常数来减少平均内存占用
- 分页优化器,用于管理内存峰值
原文实现:单个 48G 的 GPU 显卡上微调 65B 的参数模型,保持 16 字节微调任务的性能
实战
基于 GLM 4, Llama 3.1 或 Qwen2, 微调一个同时具有 NLU 和问答能力对话机器人
11.1、数据源
酒店预订场景
https://github.com/thu-coai/CrossWOZ
酒店数据库
https://github.com/thu-coai/CrossWOZ/blob/master/data/crosswoz/database/hotel_db.json
11.2、数据增强
- 从 CrossWOZ 数据集中抽取了只关于酒店的对话
- 利用 ChatGPT 进行如下修改和补充
- 对设施的描述更口语化
- “找一家有国际长途电话的酒店” -> “找一家能打国际长途的酒店”
- 补充一定比例的多轮问答,和结束语对话(p=0.3)
- 针对只提及一个酒店时的问答:“这个酒店的电话是多少”
- 针对推荐多个酒店时的对比问答:“哪个酒店评分更高”
- 结束语:“好的,祝您入住愉快”
- 补充按酒店名(简称)、价格上限查询的对话(原数据中没有这类说法)
- 对设施的描述更口语化
数据增强的代码参考 data_augmentation.zip
最终按 8:1:1 拆分训练集、验证集和测试
原始样本
1 | [ |
增强后样本
1 | [ |
11.3、数据的基本拼接方式
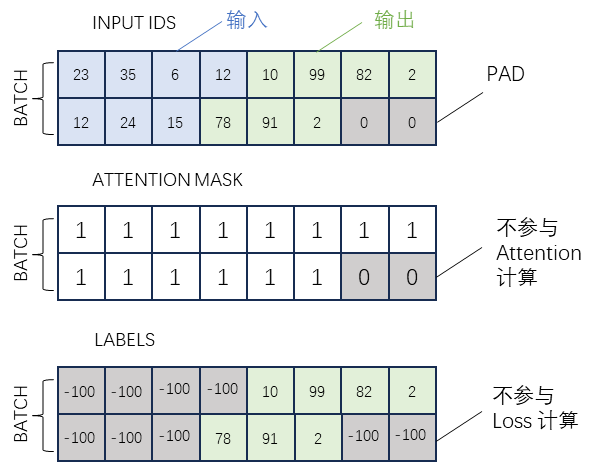
11.4、多轮对话怎么拼
方法一:ChatGLM 2 的方式
user: 你好
assistant: 有什么可以帮您
user: 你喜欢什么颜色
assistant: 喜欢黑色
user: 为什么
assistant: 因为黑色幽默
按照轮次,上述对话将被拆分成 3 个单独的样本
- 每个样本以之前的历史为输入
- 当前轮的回复为输出
样本 1
输入:
[Round 0]\n
问: 你好\n
答:
输出:
有什么可以帮您
样本 2
输入:
[Round 0]\n
问: 你好\n
答: 有什么可以帮您\n
[Round 1]\n
问: 你喜欢什么颜色\n
答:
输出:
喜欢黑色
样本 3
输入:
[Round 0]\n
问: 你好\n
答: 有什么可以帮您\n
[Round 1]\n
问: 你喜欢什么颜色\n
答: 喜欢黑色\n
[Round 2]\n
问: 为什么\n
答:
输出:
因为黑色幽默
方法二:ChatGLM 3 / GLM4-9B 的方式
因为 CausalLM 是一直从左往右预测的,我们可以直接在多轮对话中标识出多段输出。
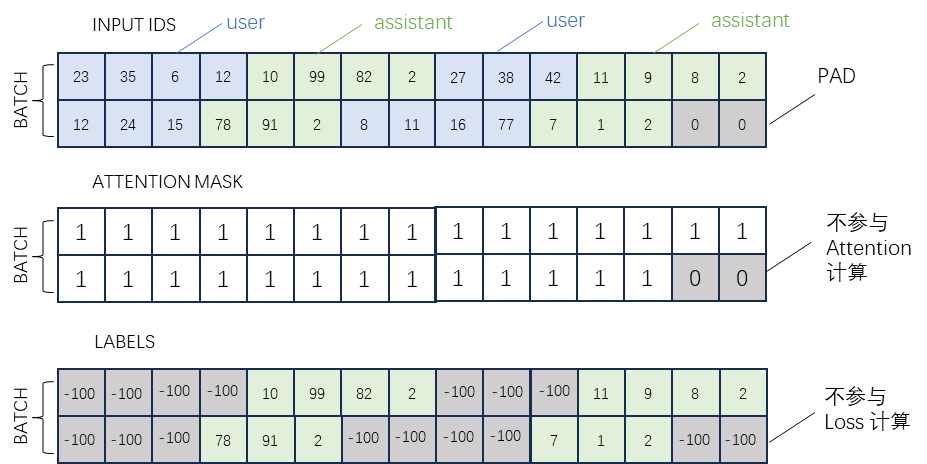
具体如下:
角色special token用于标识分隔出多轮对话,同时也可以防范注入攻击
<|system|>#系统提示词,指明模型可使用的工具等信息<|user|>#用户输入,用户的指令<|assistant|>#模型回复,或模型思考要做的事情<|observation|>#工具调用、代码执行结果
注意:这里<|role|>这种是一个 token,而不是一串文本,所以不能通过tokenizer.encode('<role>')来得到
角色后跟随的是 metadata,对于 function calling 来说,metadata 是调用的函数和相应参数;对其他角色的对话,metadata 为空
- 多轮对话 finetune 时根据角色添加 loss_mask
- 在一遍计算中为多轮回复计算 loss
<|system|>你是一个名为 GhatGLM 的人工智能助手。你是基于智谱AI训练的语言模型 GLM-4 模型开发的,你的任务是针对用户的问题和要求提供适当的答复和支持。\n\n# 可用工具\n\n## function_name1\n\n{…}\n\n## function_name2\n\n{…}\n在调用上述函数时,请使用 Json 格式表示调用的参数。”
<|user|> 北京的天气怎么样?
<|assistant|> get_weather\n{“location”:”北京”}
<|observation|> {“temperature_c”: 12, “description”: “haze”}
<|assistant|> 根据天气工具的信息,北京的天气是:温度 12 摄氏度,有雾。
<|user|> 这样的天气适合外出活动吗?
<|assistant|> 北京现在有雾,气温较低,建议您考虑一下是否适合外出进行锻炼。
<|user|>
高亮部分为需要计算 loss 的 token。注意<|assistant|>后的内容和角色 token 都需要算 loss。
此部分可以参考 GLM4 的官方实现: tokenizer 的代码中的 apply_chat_template 方法。
格式化后的数据样例
1 | { |
- 在 messages 字段中组织对话轮次
- 在 tools 的定义放在 system 角色中,描述 function 和 parameters 的定义
- 以 user 和 assistant 标识出用户输入与系统回复
- 在 function call 的角色为 assistant,格式为 function_name\n{"arg":"val", ...}
- 以 observation 标识出 function 的返回结果
11.5、如何在 Llama3/Qwen2 中实现类似 Function Calling 的效果
- 我们自定义 user、assistant、search、return 四个角色
- 因为只有一个 function,我们直接把 function 标识成 search
- 每轮 assistant 和 search 前缀也由模型自动生成,我们以此判断是 function 还是文本回复
- 类似 GLM4-9b,我们以预留的特殊 token,来标识每个轮次的角色和轮次结束
- 例如:
<|start_header_id|>角色<|end_header_id|>内容 … …<|eot_id|> - 其中
<|start_header_id|>,<|end_header_id|>,<|eot_id|>是 Llama 3 预留的特殊 token
- 例如:
Function Call 的样例
输入
<|start_header_id|>user<|end_header_id|>你好,请帮我推荐一个提供无烟房的舒适型酒店可以吗?<|eot_id|>
输出
<|start_header_id|>search<|end_header_id|>{"facilities": ["无烟房"], "type": "舒适型"}}<|eot_id|>
文本回复的样例
输入
<|start_header_id|>user<|end_header_id|>你好,请帮我推荐一个提供无烟房的舒适型酒店可以吗?<|eot_id|>
<|start_header_id|>search<|end_header_id|>{"facilities": ["无烟房"], "type": "舒适型"}}<|eot_id|>
<|start_header_id|>return<|end_header_id|>[{"name": "北京红驿栈酒店", "type": "舒适型", "address": "北京朝阳区东直门外春秀路太平庄 10 号(主副楼在一幢建筑里)", "subway": "东直门地铁站 E 口", "phone": "010-64171066", "facilities": ["公共区域和部分房间提供 wifi", "宽带上网", "国际长途电话", "吹风机", "24 小时热水", "暖气", "无烟房", "早餐服务", "接待外宾", "行李寄存", "叫醒服务"], "price": 344.0, "rating": 4.7, "hotel_id": 51}, {"name": "维也纳国际酒店(北京广安门店)", "type": "舒适型", "address": "北京西城区白广路 7 号", "subway": "广安门内地铁站 C 口", "phone": "010-83539988", "facilities": ["酒店各处提供 wifi", "宽带上网", "吹风机", "24 小时热水", "中式餐厅", "会议室", "无烟房", "商务中心", "早餐服务", "洗衣服务", "行李寄存", "叫醒服务"], "price": 553.0, "rating": 4.7, "hotel_id": 56}]}]<|eot_id|>
输出
<|start_header_id|>assistant<|end_header_id|>没问题,推荐你去北京红驿栈酒店和维也纳国际酒店(北京广安门店),都挺好的。<|eot_id|>
11.6、编写训练代码
见附件: fine-tuning-lab.zip
11.7、训练后,在测试集上的参考指标
- 针对 Function Calling 的每个参数(即 Slot),我们评估准确率、召回率、F1 值
- 针对文本回复,我们评估输出文本与参考文本之间的 BLEU Score
- 如果本该是 Function Calling 的轮次,模型回复了文本,则所有指标为 0,反之 BLEU Score 为 0
| Model | Method | BLEU-4 | SLOT-P | SLOT-R | SLOT-F1 |
|---|---|---|---|---|---|
| GLM4-9B | Functional Call | 53.53 | 82.79 | 73.47 | 77.85 |
| QLoRA | 67.41 | 95.95 | 96.74 | 96.34 | |
| Llama3.1-8B | Prompt | 51.94 | 92.55 | 87.84 | 90.19 |
| QLoRA | 66.53 | 97.23 | 95.98 | 96.60 | |
| Qwen2-7B | Prompt | 23.43 | 85.21 | 88.91 | 88.02 |
| LoRA | 66.70 | 96.42 | 95.34 | 95.87 |
数据准备与处理
12.1、数据采集
- 自然来源(如业务日志):真实数据
- Web 抓取:近似数据
- 人造
12.2、数据标注
- 专业标注公司
- 定标准,定验收指标
- 预标注
- 反馈与优化
- 正式标注
- 抽样检查:合格->验收;不合格->返工
- 众包
- 定标准,定检验指标
- 抽样每个工作者的质量
- 维系高质量标注者社区
- 主动学习:通过模型选择重要样本,由专家标注,再训练模型
- 设计产品形态,在用户自然交互中产生标注数据(例如点赞、收藏)
12.3、数据清洗
- 去除不相关数据
- 去除冗余数据(例如重复的样本)
- 去除误导性数据(业务相关)
12.4、样本均衡性
- 尽量保证每个标签(场景/子问题)都有足够多的训练样本
- 每个标签对应的数据量尽量相当
- 或者在保证每个标签样本充值的前提下,数据分布尽量接近真实业务场景的数据分布
- 数据不均衡时的策略
- 数据增强:为数据不够类别造数据:(1)人工造;(2)通过模板生成再人工标注;(3)由模型自动生成(再人工标注/筛选)
- 数据少的类别数据绝对数量也充足时,Downsample 一般比 Upsample 效果好
- 实在没办法的话,在训练 loss 里加权(一般不是最有效的办法)
- 根据业务属性,保证其他关键要素的数据覆盖,例如:时间因素、地域因素、用户年龄段等
12.5、数据集构建
- 数据充分的情况下
- 切分训练集(训练模型)、验证集(验证超参)、测试集(检验最终模型+超参的效果)
- 以随机采样的方式保证三个集合的数据分布一致性
- 在以上三个集合里都尽量保证各个类别/场景的数据覆盖
- 数据实在太少
- 交叉验证
- 占用显存的大头主要分为四部分:模型参数、前向计算过程中产生的中间激活、后向传递计算得到的梯度、优化器状态。
- HuggingFace 官方推出一个在线工具,可以估算模型的显存使用情况。





