
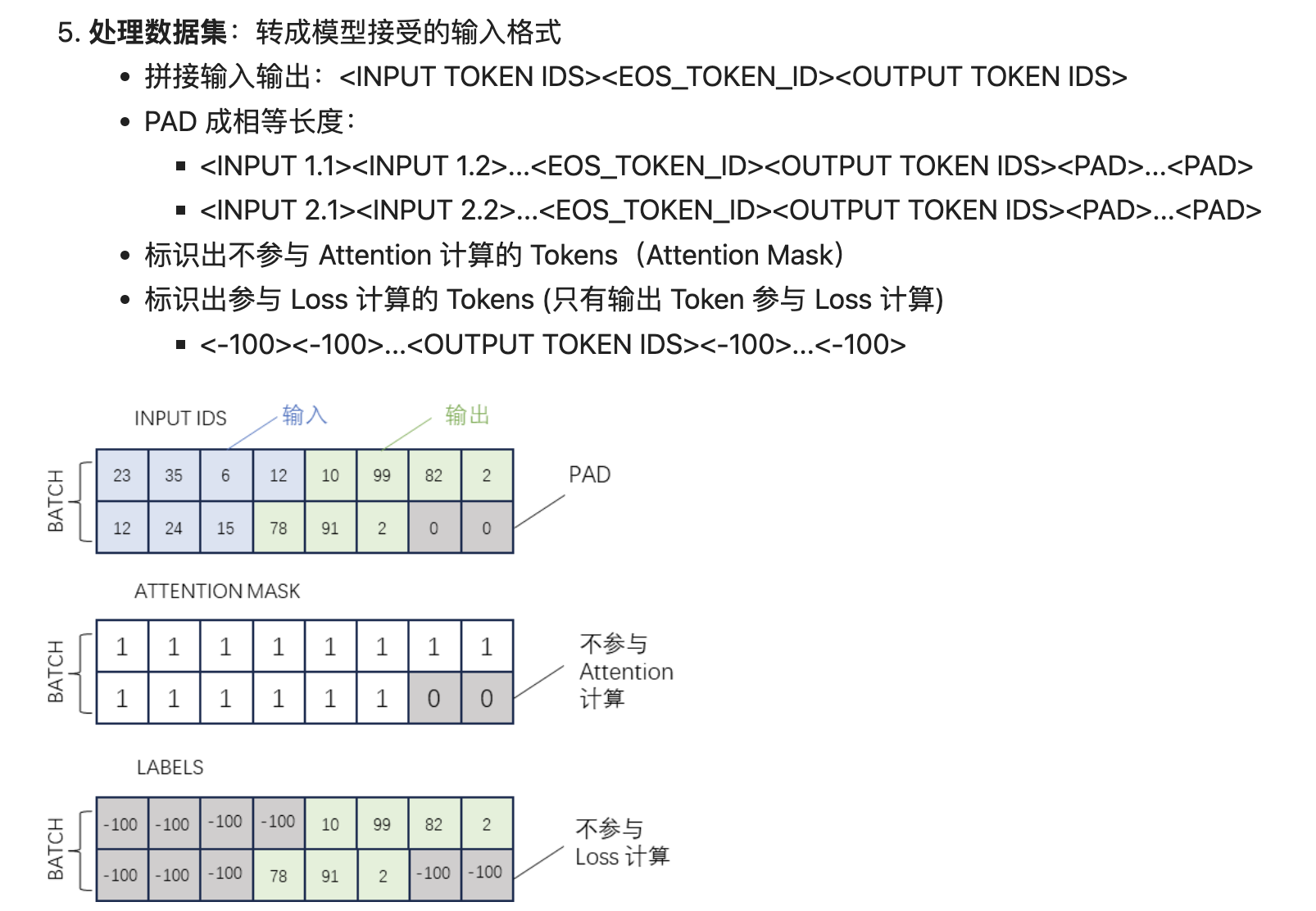
11、Agent微调
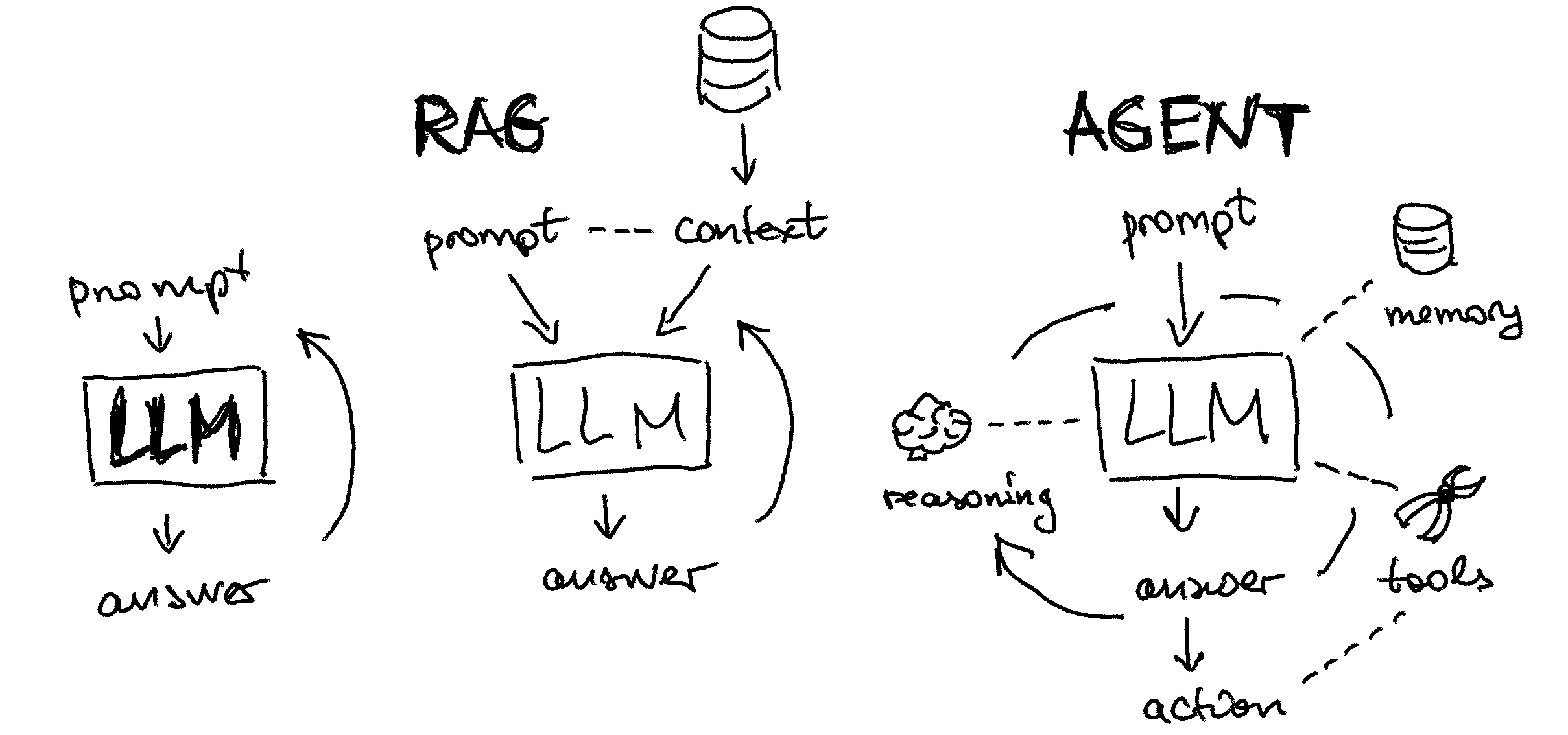
1. 认识大模型 Agent
1.1 大模型 Agent 的应用场景
- 帮我订一张周五去上海的机票;
- 请帮我约一个和搜索产品部的需求沟通会,本周三至周五我日历上空闲的时间都可以。
【重点】大模型应用需要 Agent 技术的原因:
- 大模型的“幻觉”问题,很难在从模型本身上彻底解决,在严肃的应用场景需要通过引入外部知识确保答案的准确;
- 大模型参数无法做到实时更新,本身也无法与真实世界产生实时连接,在多数场景下难以满足实际需求;
- 复杂的业务场景,不是一问一答就能解决的,需要任务拆解、多步执行与交互。
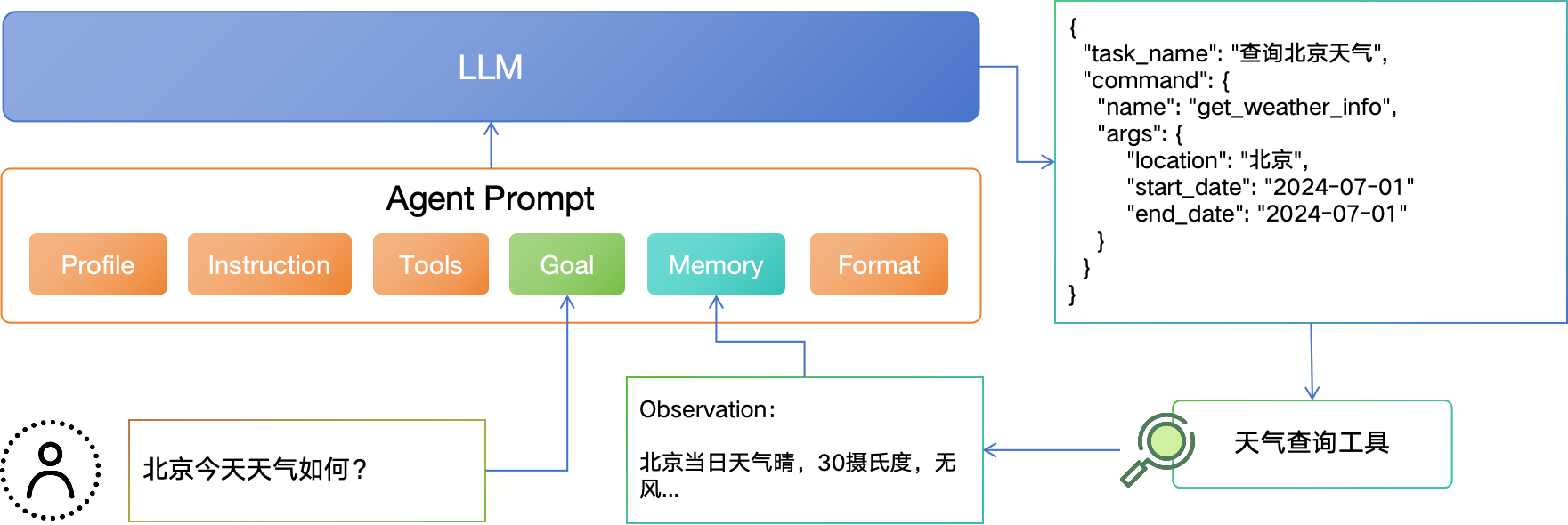
大模型应用,不仅要“会说话”,更要“会做事”!
1.2 大模型 Agent 的技术框架
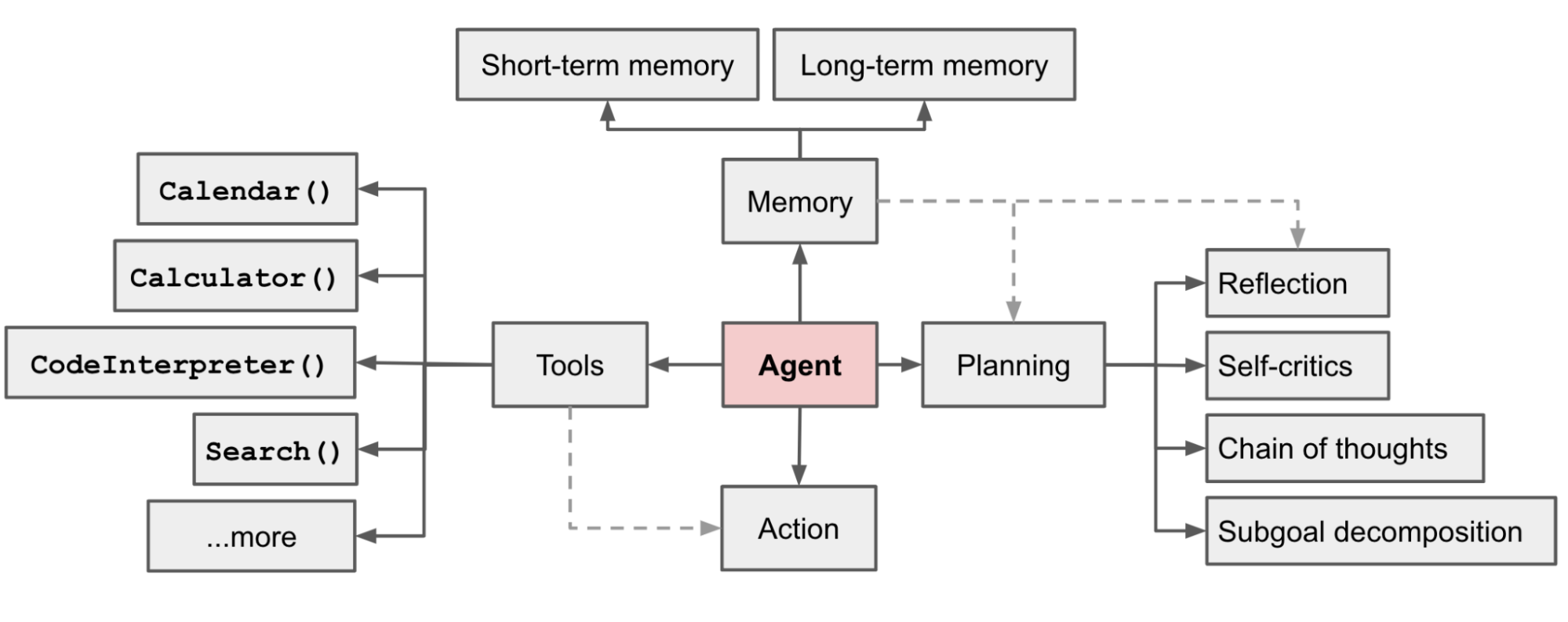
1.3 为什么需要做 Agent Tuning ?
如何实现 Agent?利用 Prompt Engineering 可以实现吗?
答案显然是可以!前面学的 AutoGPT 就是例子。
既然通过 Prompt Engineering 可以实现 Agent,那为什么还要训练 Agent 模型呢?
【重点】因为可以这么做的前提是:模型足够“聪明”,靠看“说明书”就能执行, Prompt Engineering 实际上是把“说明书”写得更加清晰易懂。
- 实践证明,除了 GPT-4 level 的大模型,其他大模型(包括 GPT-3.5 )无法很好遵从 prompt 要求完成复杂的 Agent 任务;
- 在很多实际应用场景,无法使用最强的大模型 API ,需要私有化部署小模型,需要控制推理成本;
- 通过训练,一个小参数量的大模型(13B、7B等)也能达到较好的能力,更加实用。
训练 Agent 模型,可以看做是“案例学习”,在“说明书”的基础上,再通过真实的案例来“强化培训”。
1.4 Agent Tuning 的研发流程

训练成本参考:
训练框架: HuggingFace Trainer + DeepSpeed Zero3
配置说明:max_len:4096 + Flash Attention + bf16 (batchsize=1、AdamW优化器)
| 模型 | 训练最低配置 | 训练数据规模(token数) | 建议训练 epoch 数 | 平均训练时长 | 训练成本(估算) |
|---|---|---|---|---|---|
| 7B (全参数) | 4卡A100(4 * 80G) | 470M | 5 | 25h * 5 = 125h | 34.742 * 4 * 125 = 17371.0 元 |
| 14B (全参数) | 8卡A100(8 * 80G) | 470M | 4 | 24h * 4 = 96h | 34.742 * 8 * 96 = 26681.9 元 |
| 72B (全参数) | 32卡A100(32 * 80G) | 470M | 2 | 40h * 2 = 80h | 34.742 * 32 * 80 = 88939.5 元 |
2. Agent Prompt 模板设计
常见的 Agent Prompt 模板,除了大家学习过的 AutoGPT 外,还有 ReACT、ModelScope、ToolLLaMA 等不同的形式。
2.1 主流 Agent Prompt 模板
| 模版 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| ReACT | ReACT prompt较为简单,先设定Question,再以Thought、Action、Action Input、Observation执行多轮,最后输出Final Answer | prompt 简单 | 1. API 参数只能有一个 2. 没有设定反思等行为,对于错误的思考不能及时纠正 |
| ModelScope | 更为直接的生成回复,调用只需要加入<|startofthink|>和<|endofthink|>字段,并在其中填入command_name和args | 简单直接 | 没有设定反思等行为,对于错误的思考不能及时纠正 |
| AutoGPT | - prompt 较为复杂,分为生成工具调用 和 生成最终答案 两套prompt - 生成工具调用 prompt 详细设立了Constraints(例如不需要用户协助)、Resources(例如网络搜索)、Best Practices(例如每个API都需要花费,尽量少的调用),最终严格以json格式输出 | prompt 限制多,会较好地进行自我反思、任务规划等 | prompt 较长,花费较大 |
| ToolLLaMA | 模仿AutoGPT和ReACT,输出以Thought、Action、Action Input 格式而非 json 格式,增加了 give_up_and_restart,支持全部推导重来,重来的prompt会把历史失败的记录加进去训模型用了1.6w Rapid API | prompt 限制多,会较好地进行自我反思、任务规划等,并支持全部推倒重来 | 1. prompt 较长,花费较大 2. 全部推倒重来花费会更大 |




1 | # 导入依赖库 |
ChatCompletion(id='chatcmpl-A6dGZGo97mkcsE3VTR47qwbltemLz', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Thought: I now know the final answer\nFinal Answer: 北京的天气是22°C,天气晴朗。', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1726144271, model='gpt-4o-mini-2024-07-18', object='chat.completion', service_tier=None, system_fingerprint='fp_483d39d857', usage=CompletionUsage(completion_tokens=23, prompt_tokens=210, total_tokens=233))
------------------------------------------
Thought: I now know the final answer
Final Answer: 北京的天气是22°C,天气晴朗。
2.2 Agent Prompt 模板设计
我们可以设计两套Prompt模板,一套用于任务规划和工具调用指令生成(模板-1),一套用于总结生成最终答案(模板-2)。










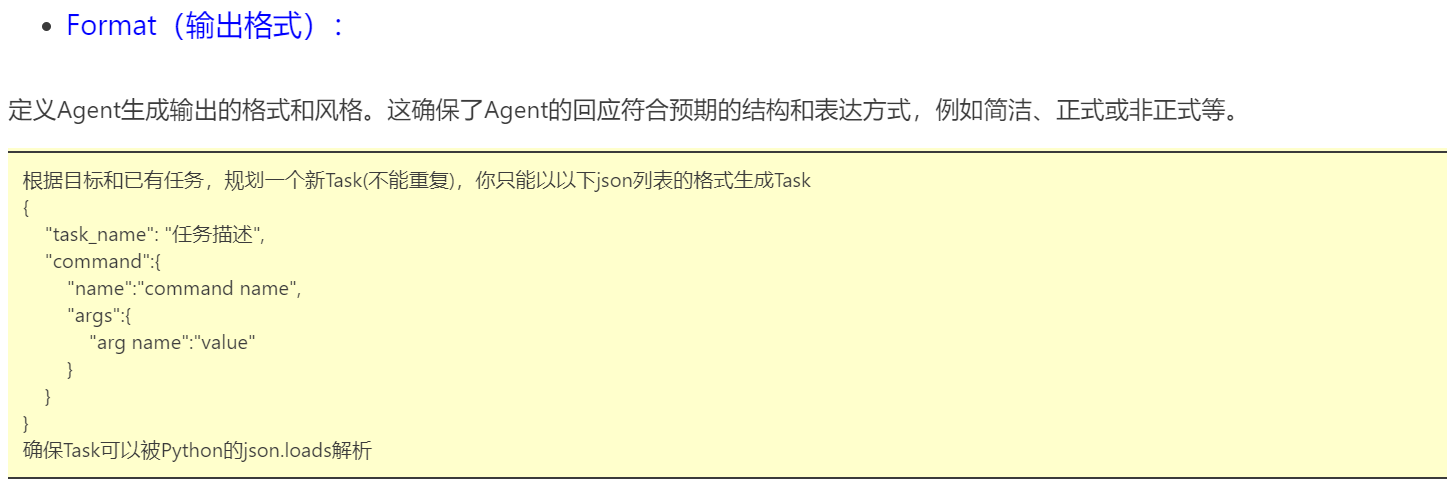

Prompt示例
1 | # 导入依赖库 |
ChatCompletion(id='chatcmpl-A6dYqR8V3JFO0SM3ZHLjzGK59wZIl', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='{\n "task_name": "获取北京现在的天气信息",\n "command":{\n "name":"get_weather_info",\n "args":{\n "location":"Beijing",\n "start_date":"2024-09-12",\n "end_date":"2024-09-12",\n "is_current":"yes"\n }\n }\n}', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1726145404, model='gpt-4-0613', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=76, prompt_tokens=1069, total_tokens=1145))
------------------------------------------
{
"task_name": "获取北京现在的天气信息",
"command":{
"name":"get_weather_info",
"args":{
"location":"Beijing",
"start_date":"2024-09-12",
"end_date":"2024-09-12",
"is_current":"yes"
}
}
}

1 | # 导入依赖库 |
ChatCompletion(id='chatcmpl-A6dccbf7NniBdcsNNTjKOKZ6JfMvd', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='根据我获取的信息,现在北京的天气状况是晴朗,气温为18.1摄氏度,气压为1013.0百帕,湿度为88%,体感温度为18.1摄氏度,能见度为10.0公里。空气质量方面,PM2.5为48.28微克/立方米,PM10为70.3微克/立方米。', refusal=None, role='assistant', function_call=None, tool_calls=None))], created=1726145638, model='gpt-4-0613', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=123, prompt_tokens=332, total_tokens=455))
------------------------------------------
根据我获取的信息,现在北京的天气状况是晴朗,气温为18.1摄氏度,气压为1013.0百帕,湿度为88%,体感温度为18.1摄氏度,能见度为10.0公里。空气质量方面,PM2.5为48.28微克/立方米,PM10为70.3微克/立方米。
3. Agent Tuning
3.1 Agent Tuning 的目的(再次理解)
- 实践证明,除了 GPT-4 level 的大模型,其他大模型(包括 GPT-3.5 )无法很好遵从 prompt 要求完成复杂的 Agent 任务;
- 在很多实际应用场景,无法使用最强的大模型 API ,需要私有化部署小模型,需要控制推理成本;
- 通过训练,一个小参数量的大模型(13B、7B等)也能达到较好的能力,更加实用。
训练 Agent 模型,可以看做是“案例学习”,在“说明书”的基础上,再通过真实的案例来“强化培训”。
3.2 训练数据准备

【重点】大模型 Fine Tuning 本质上是在给定输入 Input 的条件下,调整模型的参数,使得大模型生成的输出内容 Output’ 和训练数据中的标准回答 Output 尽可能接近。Fine Tuning 也被称作 Supervised Fine Tuning,简称SFT,有监督微调,训练数据中的 Output 就是用来“监督”模型参数调整方向的。
Agent Tuning 是一种特殊的 fine-tuning,有时也被称作 Tool SFT,特殊之处在于:
1)Agent Tuning 的 Prompt 更复杂,约束条件更多;
2)通常 Agent 工作过程是多步的,因此训练数据也需要是多步骤的,多步之间前后有关联。
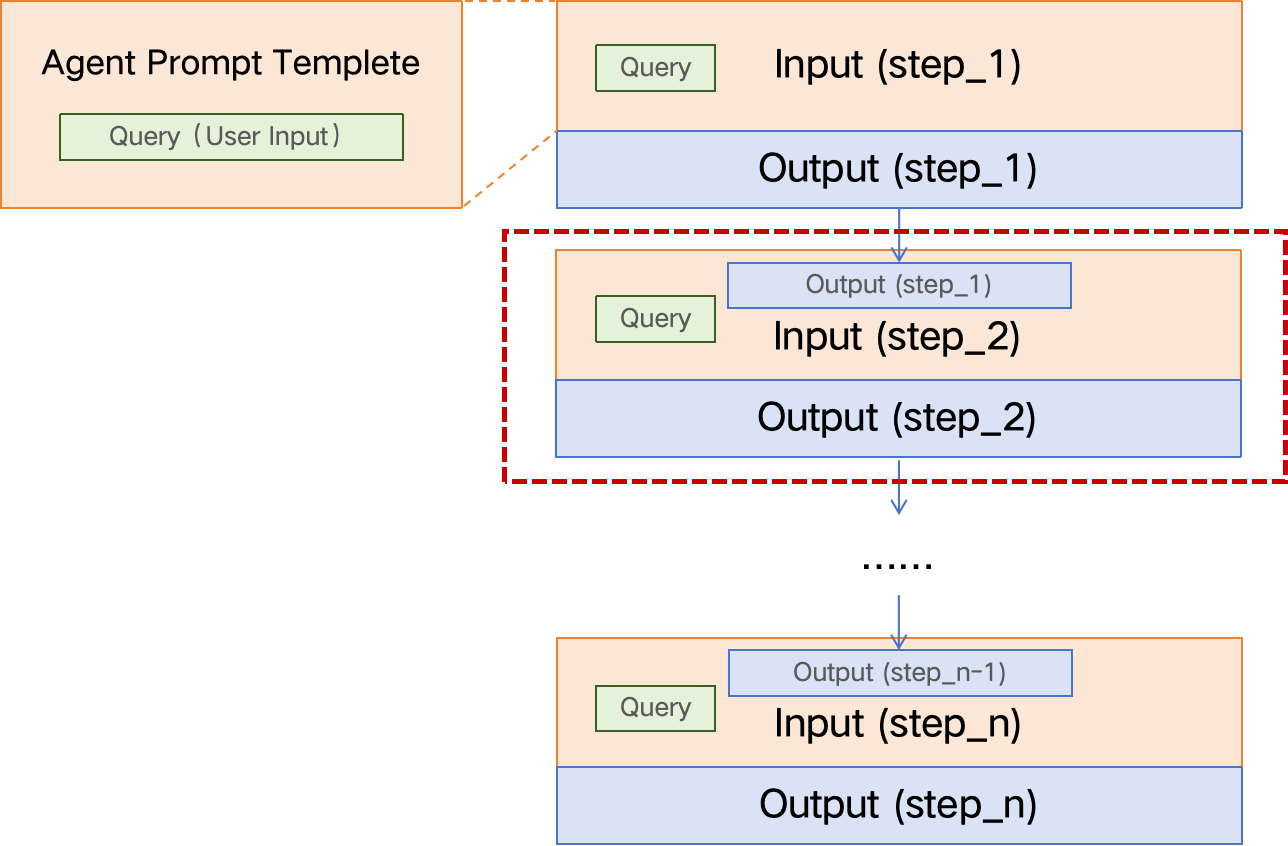
【重点】Agent Tuning 训练数据构建的步骤:
- 根据实际业务收集大量 query,要尽可能覆盖各种场景;
- 将每一个 query 与 prompt 模板结合,构成 agent prompt,也就是训练数据中的输入部分;
- 为每一个 agent prompt 构建对应的标准答案,也就是训练数据中的输出部分,这项工作可以借助 GPT-4 level 的大模型来降本提效;
- 如果第三步是用大模型来生成答案,则最好通过人工修正或筛选高质量的 Output,数据质量越高,最终 Agent Tuning 得到的模型效果越好。
- 训练数据样例:
3.3 模型训练

注意:Agent 模型通常需要全参数训练,LoRA 效果不好。
3.4 效果评估
3.4.1 自动评估
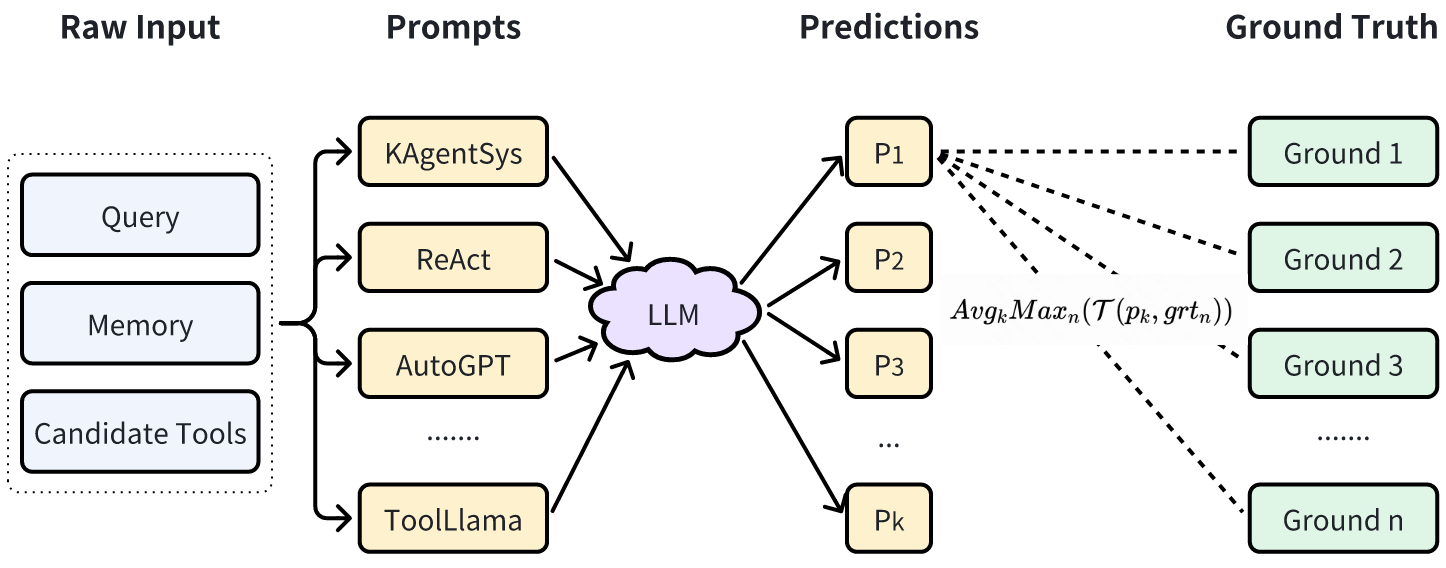
自动评估的主要目的是在模型训练过程中监控模型的效果,评估指标的对比意义大于绝对值意义。
- 采用 GPT-4 + 人工修正的方式构建自动评测的 benchmark(一般从训练数据中随机分出一部分即可);
- 将 Agent 输出结果与 benchmark 中的参考答案进行对比,计算得到分值。
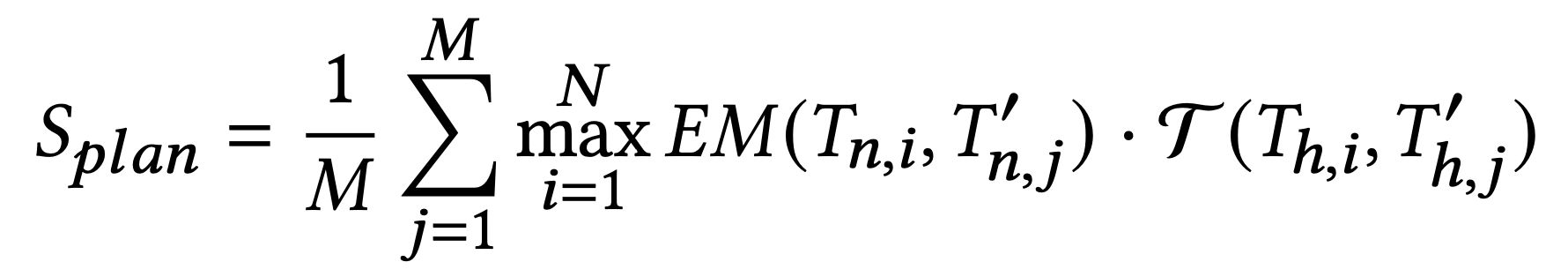
其中,$ T_{n,i} $ 为 Groud Truth 中的工具名称,$ T’_{n,j} $ 为 待测试的 Agent Response 中的工具名称,EM为精确匹配(Exact Match,直接进行字符串精确匹配),结果为 0 或 1;
$ T_{h,i} $ 为 Groud Truth 中的任务描述(示例中的“task_name”),$ T’_{h,j} $ 为 待测试的 Agent Response 中的任务描述,![]() 可以是任何文本生成质量评估的方法(例如 ROUGE、 BLEU),做模糊匹配评分,分值为0-1;
可以是任何文本生成质量评估的方法(例如 ROUGE、 BLEU),做模糊匹配评分,分值为0-1;
类似地:
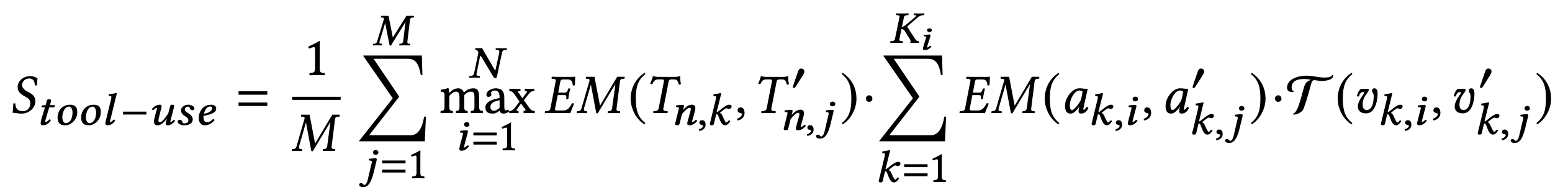
自动测试结果示例:
| Scale | Planning | Tool-use | Reflection | Concluding | Profile | Overall Score | |
|---|---|---|---|---|---|---|---|
| GPT-3.5-turbo | - | 18.55 | 26.26 | 8.06 | 37.26 | 35.42 | 25.63 |
| Qwen | 7B | 13.34 | 18.00 | 7.91 | 36.24 | 34.99 | 21.17 |
| Qwen2 | 7B | 20.11 | 29.03 | 21.01 | 40.36 | 42.06 | 29.57 |
| Baichuan2 | 13B | 6.70 | 16.10 | 6.76 | 24.97 | 19.08 | 14.89 |
| — | — | — | — | — | — | — | — |
| Qwen-MAT | 7B | 31.64 | 43.30 | 33.34 | 44.85 | 44.78 | 39.85 |
| Baichuan2-MAT | 13B | 37.27 | 52.97 | 37.00 | 48.01 | 41.83 | 45.34 |
4.3.2 人工评估
最靠谱的评估当然还是需要人工来做,人工评估的难点在于标准的制定,以及对评估人员的培训。
评估标准示例:
评分分为五个等级,具体定义如下:
1分:核心信息存在重大不准确性,大部分或全部内容不正确;
2分:核心信息不正确,或超过60%的内容有错误;
3分:核心信息准确,但10%到60%的补充信息不正确;
4分:小有出入,核心信息准确,补充信息中的错误不超过10%;
5分:完全正确。
得分为4分或5分的回答被认为是可用的。
遇到违规内容一票否决,直接判0分。
……
人工评估效率低、成本高,所以不能频繁使用,一般在大的模型版本上使用。
4. Agent 泛化性提升
如果想进一步提升 Agent 的泛化性,比如希望用一个 Agent 服务于多个业务,能适应不同的 Prompt 模板,可以灵活地接入新的业务,那么训练数据应该如何构建呢?
4.1 训练数据的多样性
基座大模型本身的理解能力和 Agent Tuning 训练数据的多样性共同决定了 Agent 的泛化能力。在指定了基座模型的情况下,我们可以做的是提升训练数据的多样性。
我们可以将训练数据 Input 部分拆解为3个变量:Query、Tools、Agent Prompt模板,最终的数据就是这3个变量的组合。
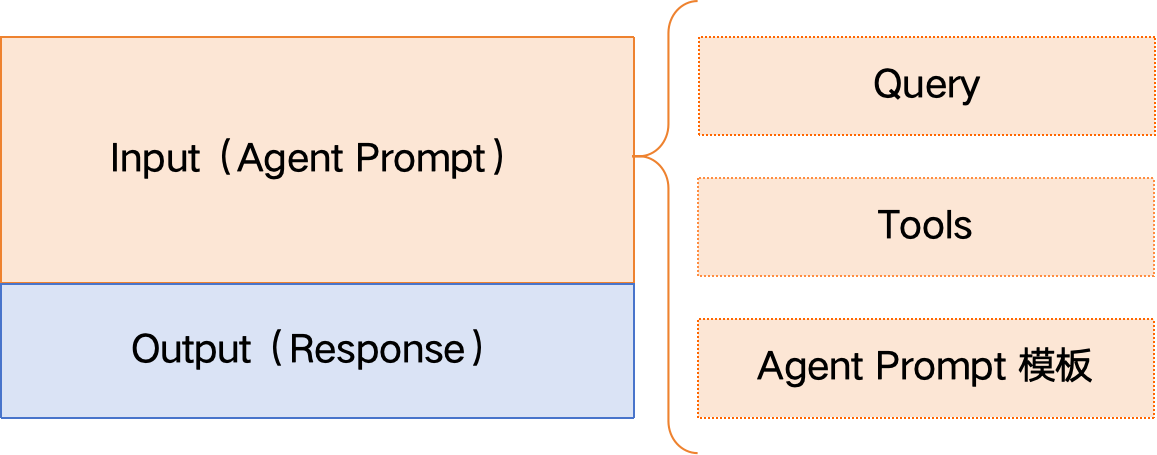



【重点】对 Query、Tools、Agent Prompt 模板 这三个变量分别构造了各种类型的数据,然后进行组合构成多样性的 Input( Prompt )数据,再调用GPT-4生成 Output( Response ),多样性的数据可以使模型不只拟合特定的 Prompt 模板,适应各种类型的 Query 以及 Tools 集合,提高模型的泛化性。
4.2 Meta-Agent
Agent Prompt 模板多样性提升
4.2.1 背景
ReACT、ToolLlama、ModelScope、AutoGPT 都有一套各自运行在其中内部的一套 prompt 模板,模型如果只是在一套 prompt 模板下训练,那么可能只是拟合了这一套 prompt ,如果换一套 prompt 性能会急剧下降;我们希望 Agent 不受到特定 Prompt 模板的限制,提升模型本质的 Agent 能力,提出了核心思想 Meta-Agent 方法。
这些 Agent Prompt 模板虽然表述方式各不相同,但都可以分为 <Profile>、<Instruction>、<Tools>、<Goal>、<Memory>、<Format>部分,那是不是可以调用GPT4来自动化生成包含这些部分且表达方式多样性的模板呢?
4.2.2 方法
我们可以通过 Prompt Engineering 来设计一个基于 GPT-4 的 Agent,用于生成多样性的 Agent Prompt 模板,我们称之为:Meta-Agent (元-Agent)。
Meta-Agent Prompt: 用于调用 GPT-4 生成 Agent Prompt 模板的 Prompt,我们称之为 Meta-Agent Prompt。
我们可以手动写一个固定的 Meta-Agent Prompt 作为 GPT-4 的输入,利用大模型内容生成的多样性来生成不同的模板,但实际上多样性效果有限,更好的方式是用不同的种子 query 做引导,提升多样性。
- 根据实际业务收集大量 query,要尽可能覆盖各种场景;
- 选取相似的数条 query 组成多个集合,如果数量不足,这一步也可以借助 GPT-4 来对 query 做扩展;
- 设计一个 Meta-Agent Prompt 模板,将不同的 query 集合插入设计好的模板中组合成不同的 Meta-Agent Prompt;
- 调用 GPT-4 生成不同的 Agent Prompt 模板候选。
利用这种方法便可以生成包含<Profile>、<Instruction>、<Tools>、<Goal>、<Memory>、<Format>要素的多样化的模板。

由于自动化生成的 Agent Prompt 模板质量可能参差不齐,我们还需要对这些模板以及生成的训练数据进行筛选。对于关键信息缺失,有明显缺陷的的模板,我们直接删除即可。剩下的模板效果如何则需要在实际数据上检验,我们同样也可以借助 GPT-4 (做裁判)来完成。具体步骤如下:
- 将一批相同的 query 分别插入到经过验证的标杆模板中(如AutoGPT、ToolLLaMA等)和 Meta-Agent 生成的 prompt 模版中,形成 prompt pair;
- 将 prompt pair 中的两个 prompt 分别输入给GPT-4,生成对应的回复;
- 利用 GPT-4 对两个回复的质量分别打分 $score_1$(标杆模板的实例)、$score_2$(候选模板的实例),如果 $score_2 - score_1 > \epsilon$,则保留该 prompt 实例,否则删除;
- 对于同一个模板的所有实例求平均分,得到模板的得分,当分值大于一定阈值,保留该模板,否则删除该模板以及对应的prompt实例。
4.3 训练数据构建关键经验
构建机器学习训练数据是保证模型性能的关键环节。以下是一些注意事项:
数据质量:
- 准确性:确保数据的标注正确且准确。错误标注会导致模型学到错误的模式。
- 一致性:数据应该保持一致,避免同样的输入在不同记录中对应相互冲突的答案。
数据量:
- 数量:足够大的数据量有助于模型捕捉复杂的模式。数据量不足可能导致模型过拟合。
- 多样性:数据应包含尽可能多的不同情况,避免模型对某些特定模式的偏好。
数据平衡:确保各种类型的数据量相对平衡。例如对于分类问题,类别不平衡会导致模型偏向多数类。
数据增强:
- 数据扩充:对于图像、文本等数据,通过旋转、翻转、添加噪声等方法扩充数据量。
- 合成数据:在数据量不足时,考虑生成合成数据。
数据清洗:
- 去重:删除重复的数据记录,避免模型学习到重复信息。
- 提质:对于含有瑕疵的数据,合理补充修正或直接删除。
隐私和合规性:
- 隐私保护:确保数据的收集和使用符合隐私保护法规。
- 数据匿名化:对敏感数据进行匿名化处理,保护个人隐私。
数据分割:
- 训练集、验证集、测试集:将数据合理分割为训练集、验证集和测试集,确保模型的泛化能力。
- 避免数据泄漏:确保训练数据中不包含测试数据的信息,避免模型在测试时表现出非真实的高精度。
持续更新:
- 数据更新:随着时间推移,定期更新训练数据,保持模型的准确性和可靠性。
- 模型监控:监控模型性能,及时发现和解决数据相关的问题。
通过关注这些注意事项,可以提高训练数据的质量,从而构建出更准确、更可靠的机器学习模型。
5. 几个 Agent Tuning 开源项目简介
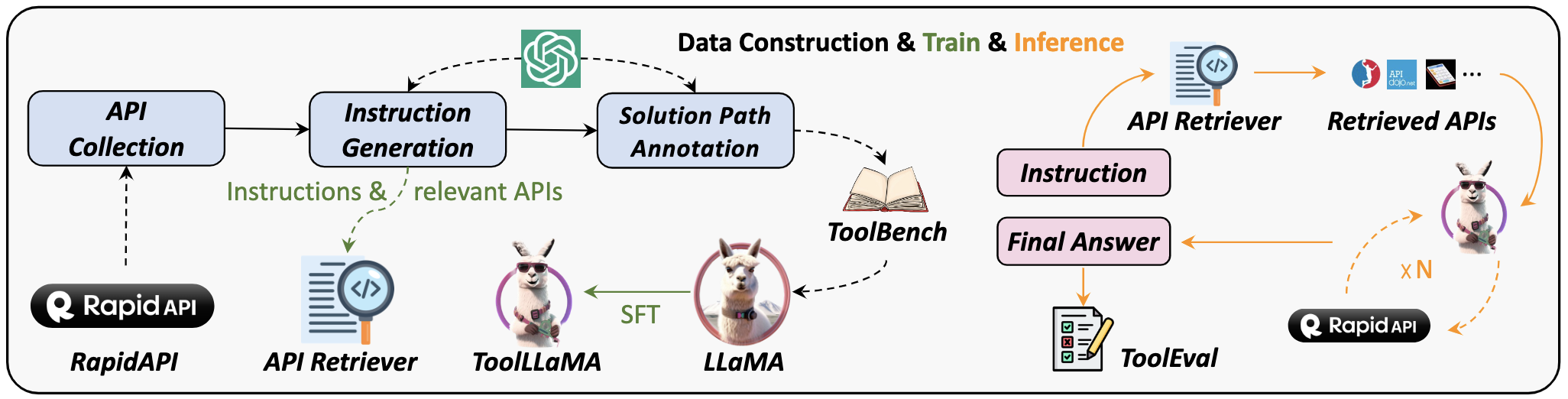
1) ToolBench (ToolLLaMA)
提供数据集、相应的训练和评估脚本,以及在ToolBench上经过微调的强大模型ToolLLaMA。
数据:ToolBench,包含 469585 条数据(工具数量:3451;API数量:16464);
模型:ToolLLaMA-2-7b-v2、ToolLLaMA-7b-v1、ToolLLaMA-7b-LoRA-v1
2) AgentTuning
- 发布机构:智谱华章
- https://github.com/THUDM/AgentTuning
利用多个 Agent 任务交互轨迹对 LLM 进行指令调整的方法。评估结果表明,AgentTuning 让 LLM 在未见过的 Agent 任务中也展现出强大的泛化能力,同时通用语言能力也基本保持不变。
数据:AgentInstruct,包含 1866 个高质量交互、6 个多样化的真实场景任务;
模型:AgentLM 由 Llama2-chat 开源模型系列在 AgentInstruct,ShareGPT 混合数据集上微调得到,有7B、13B、70B三个模型。

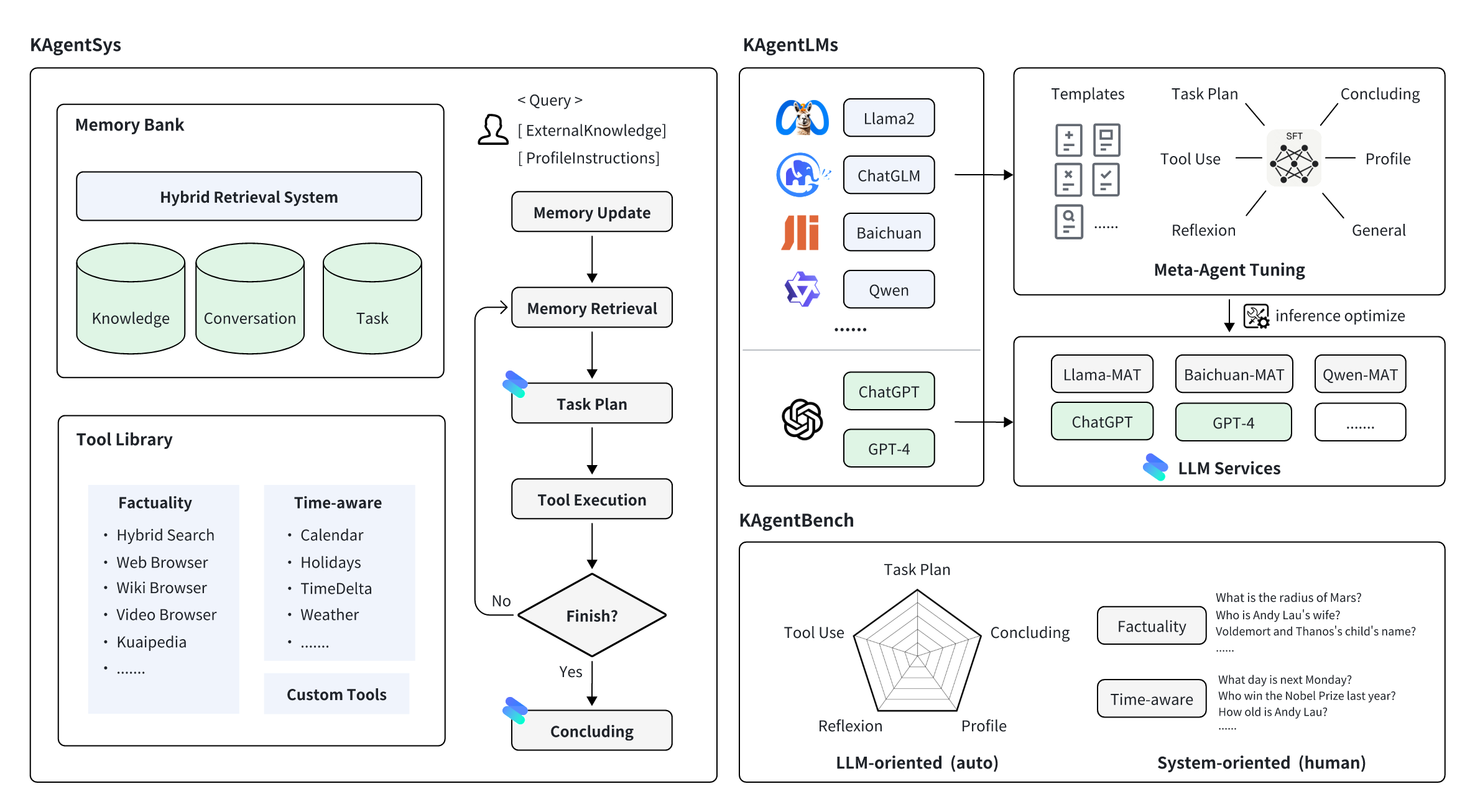
3) KwaiAgents
快手联合哈尔滨工业大学研发,使 7B/13B 的 “小” 大模型也能达到超越 GPT-3.5 的效果。
数据:KAgentInstruct,超过20w(部分人工编辑)的Agent相关的指令微调数据;KAgentBench:超过3k条经人工编辑的自动化评测Agent能力数据;
模型:采用 Meta-Agent 方法训练,包括 Qwen-7B-MAT、Qwen-14B-MAT、Qwen-7B-MAT-cpp、Qwen1.5-14B-MAT、Baichuan2-13B-MAT。
6. 总结
- 理解大模型应用需要 Agent 技术的原因:消除“幻觉”、连接真实世界、处理复杂任务;
- 理解 Agent Tuning 的主要动机:希望通过训练让大模型,尤其是小参数大模型(7B、14B)也能具备特定业务场景的 Agent 能力;
- 了解 Agent Prompt 的构造方法,通常包括Profile、Instruction、Tools、Format、Memory、Goal等部分;
- 了解 Agent Tuning 训练数据的构建方法和微调训练方式,并学习模型效果评估的方法;
- 了解提升 Agent 泛化性的方法:从Query、Tools 和 Agent Prompt 模板三个方面提升训练数据的多样化,引申了解机器学习训练数据构建的关键经验;
11、Agent微调





