
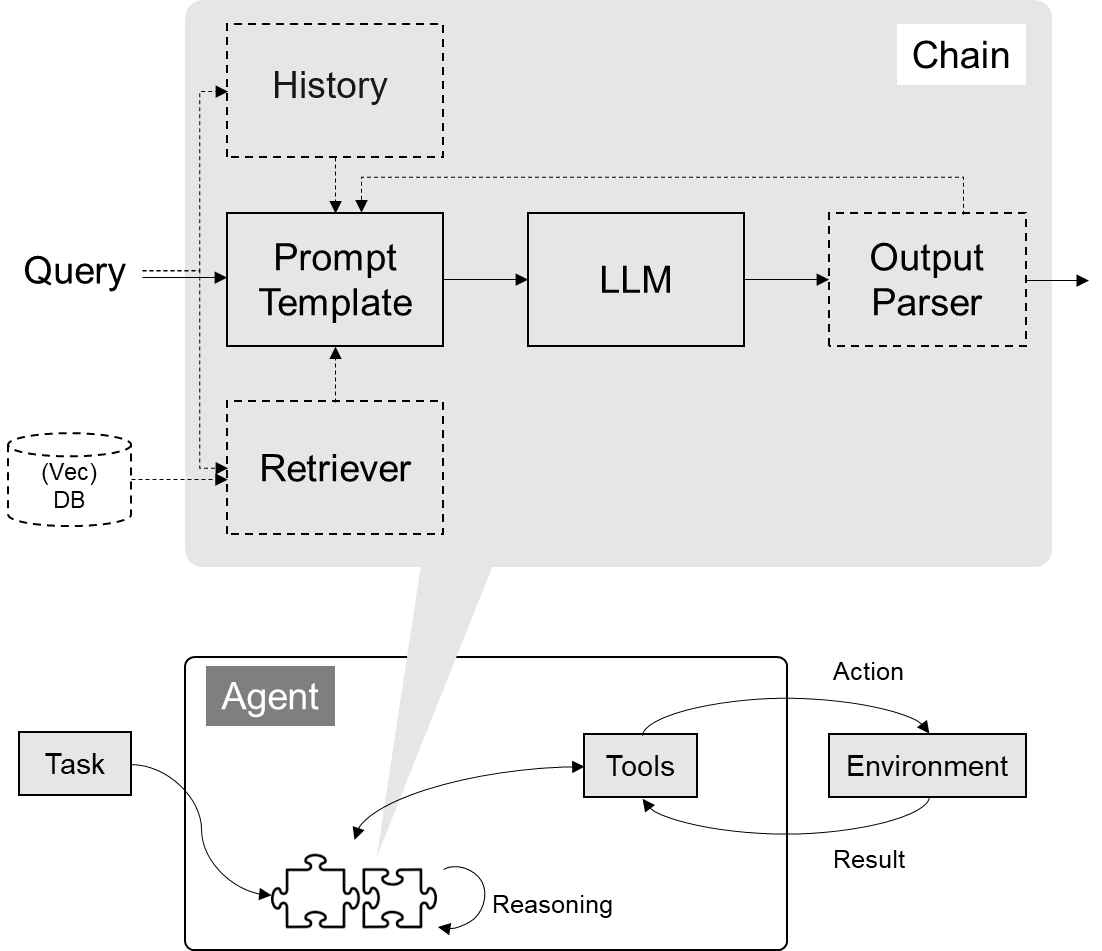
7、LangChain介绍
LangChain 的核心组件
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作(啥意思?别急,后面详细讲)
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
- 对话历史管理
- 对话历史的存储、加载与剪裁
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
- Callbacks
文档(以 Python 版为例)
- 功能模块:https://python.langchain.com/docs/get_started/introduction
- API 文档:https://api.python.langchain.com/en/latest/langchain_api_reference.html
- 三方组件集成:https://python.langchain.com/docs/integrations/platforms/
- 官方应用案例:https://python.langchain.com/docs/use_cases
- 调试部署等指导:https://python.langchain.com/docs/guides/debugging
一、模型 I/O 封装
把不同的模型,统一封装成一个接口,方便更换模型而不用重构代码。
1.1 模型 API:LLM vs. ChatModel
1 | # !pip install --upgrade langchain |
1.1.1 OpenAI 模型封装
1 | from langchain_openai import ChatOpenAI |
我是一个人工智能助手,旨在回答问题和提供信息。如果你有什么想了解的,随时问我!
1.1.2 多轮对话 Session 封装
1 | from langchain.schema import ( |
你是学员王卓然。如果你有任何问题或者需要帮助,请随时告诉我!
1.1.3 换个国产模型
1 | # !pip install qianfan |
1 | # 其它模型分装在 langchain_community 底包中 |
[INFO][2024-10-09 09:23:05.569] oauth.py:228 [t:140407762364224]: trying to refresh access_token for ak cuTPS7***
[INFO][2024-10-09 09:23:06.454] oauth.py:243 [t:140407762364224]: sucessfully refresh access_token
您好,我是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
1.2 模型的输入与输出
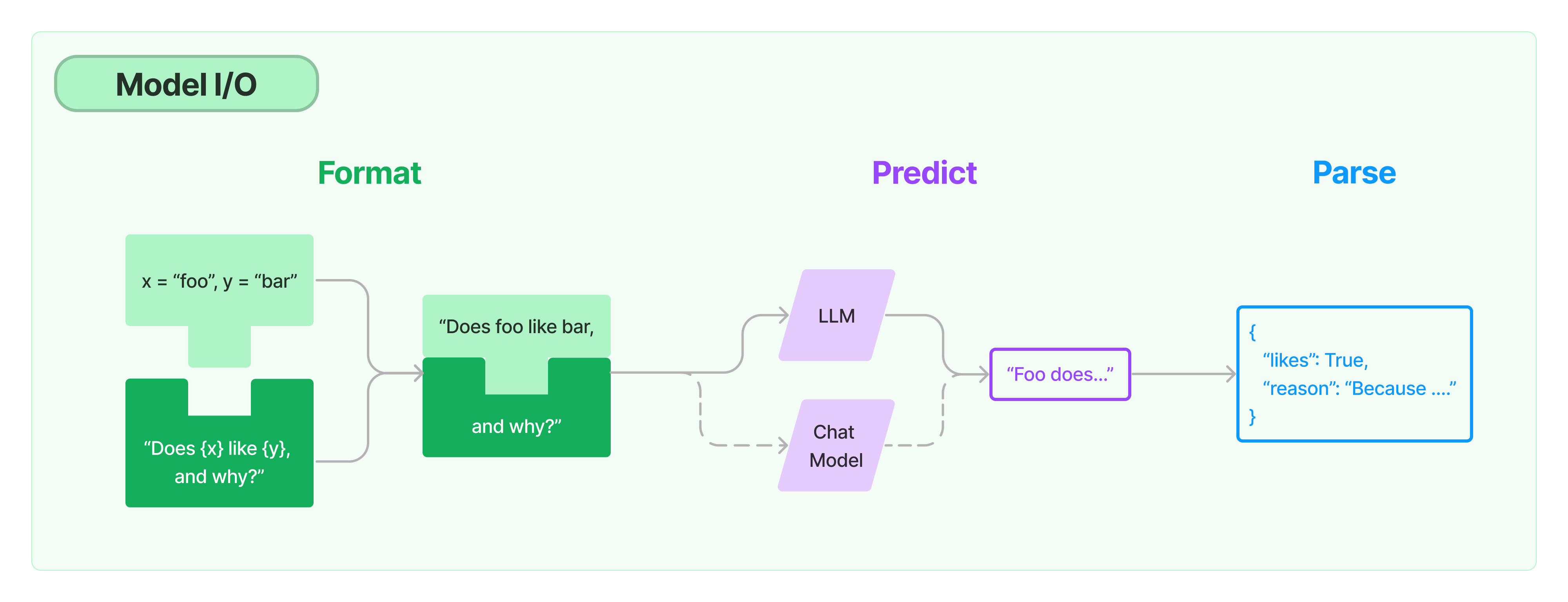
1.2.1 Prompt 模板封装
- PromptTemplate 可以在模板中自定义变量
1 | from langchain.prompts import PromptTemplate |
===Template===
input_variables=[‘subject’] input_types={} partial_variables={} template=’给我讲个关于{subject}的笑话’
===Prompt===
给我讲个关于小明的笑话
1 | from langchain_openai import ChatOpenAI |
好的,这里有一个关于小明的笑话:
小明在学校里被老师问到:“小明,你知道为什么不能在考试的时候抄袭吗?” 小明想了一会儿说:“因为如果考卷出了错,那我就跟着一起错了!” 结果全班都笑翻了。
- ChatPromptTemplate 用模板表示的对话上下文
1 | from langchain.prompts import ( |
[SystemMessage(content=’你是AGI课堂的客服助手。你的名字叫瓜瓜’, additional_kwargs={}, response_metadata={}), HumanMessage(content=’你是谁’, additional_kwargs={}, response_metadata={})]
我是AGI课堂的客服助手,名字叫瓜瓜。有什么可以帮助你的吗?
- MessagesPlaceholder 把多轮对话变成模板
1 | from langchain.prompts import ( |
1 | from langchain_core.messages import AIMessage, HumanMessage |
[HumanMessage(content=’Who is Elon Musk?’, additional_kwargs={}, response_metadata={}), AIMessage(content=’Elon Musk is a billionaire entrepreneur, inventor, and industrial designer’, additional_kwargs={}, response_metadata={}), HumanMessage(content=’Translate your answer to 中文.’, additional_kwargs={}, response_metadata={})]
1 | result = llm.invoke(messages) |
伊隆·马斯克(Elon Musk)是一位亿万富翁企业家、发明家和工业设计师。
1.2.2、从文件加载 Prompt 模板
1 | from langchain.prompts import PromptTemplate |
===Template===
input_variables=[‘topic’] input_types={} partial_variables={} template=’举一个关于{topic}的例子’
===Prompt===
举一个关于黑色幽默的例子
1.3 结构化输出
1.3.1 直接输出 Pydantic 对象
1 | from pydantic import BaseModel, Field |
1 | from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate |
Date(year=2023, month=4, day=6, era=’AD’)
1.3.2 输出指定格式的 JSON
1 | json_schema = { |
{‘year’: 2023, ‘month’: 4, ‘day’: 6}
1.3.3 使用 OutputParser
OutputParser 可以按指定格式解析模型的输出
1 | from langchain_core.output_parsers import JsonOutputParser |
原始输出:
1 | {"year": 2023, "month": 4, "day": 6, "era": "AD"} |
解析后:
{‘year’: 2023, ‘month’: 4, ‘day’: 6, ‘era’: ‘AD’}
也可以用 PydanticOutputParser
1 | from langchain_core.output_parsers import PydanticOutputParser |
原始输出:
1 | {"year": 2023, "month": 4, "day": 6, "era": "AD"} |
解析后:
Date(year=2023, month=4, day=6, era=’AD’)OutputFixingParser 利用大模型做格式自动纠错
1 | from langchain.output_parsers import OutputFixingParser |
PydanticOutputParser:
Invalid json output: ```json
{“year”: 2023, “month”: 四, “day”: 6, “era”: “AD”}
1 | OutputFixingParser: |
1 | import json |
[
{
“name”: “multiply”,
“args”: {
“a”: 3,
“b”: 4
},
“id”: “call_Cst19MWsLghWFVuZTYNHNn1N”,
“type”: “tool_call”
}
]
回传 Funtion Call 的结果
1 | messages.append(output) |
{
“content”: “3的4倍是多少?”,
“additional_kwargs”: {},
“response_metadata”: {},
“type”: “human”,
“name”: null,
“id”: null,
“example”: false
}
{
“content”: “”,
“additional_kwargs”: {
“tool_calls”: [
{
“id”: “call_Cst19MWsLghWFVuZTYNHNn1N”,
“function”: {
“arguments”: “{"a":3,"b":4}”,
“name”: “multiply”
},
“type”: “function”
}
],
“refusal”: null
},
“response_metadata”: {
“token_usage”: {
“completion_tokens”: 17,
“prompt_tokens”: 97,
“total_tokens”: 114,
“prompt_tokens_details”: {
“cached_tokens”: 0
},
“completion_tokens_details”: {
“reasoning_tokens”: 0
}
},
“model_name”: “gpt-4o-mini-2024-07-18”,
“system_fingerprint”: “fp_f85bea6784”,
“finish_reason”: “tool_calls”,
“logprobs”: null
},
“type”: “ai”,
“name”: null,
“id”: “run-a00986b2-1f52-467d-ac03-ca7bf25b9e30-0”,
“example”: false,
“tool_calls”: [
{
“name”: “multiply”,
“args”: {
“a”: 3,
“b”: 4
},
“id”: “call_Cst19MWsLghWFVuZTYNHNn1N”,
“type”: “tool_call”
}
],
“invalid_tool_calls”: [],
“usage_metadata”: {
“input_tokens”: 97,
“output_tokens”: 17,
“total_tokens”: 114,
“input_token_details”: {
“cache_read”: 0
},
“output_token_details”: {
“reasoning”: 0
}
}
}
{
“content”: “12”,
“additional_kwargs”: {},
“response_metadata”: {},
“type”: “tool”,
“name”: “multiply”,
“id”: null,
“tool_call_id”: “call_Cst19MWsLghWFVuZTYNHNn1N”,
“artifact”: null,
“status”: “success”
}
3的4倍是12。
1.5、小结
- LangChain 统一封装了各种模型的调用接口,包括补全型和对话型两种
- LangChain 提供了 PromptTemplate 类,可以自定义带变量的模板
- LangChain 提供了一些列输出解析器,用于将大模型的输出解析成结构化对象
- LangChain 提供了 Function Calling 的封装
- 上述模型属于 LangChain 中较为实用的部分
二、数据连接封装
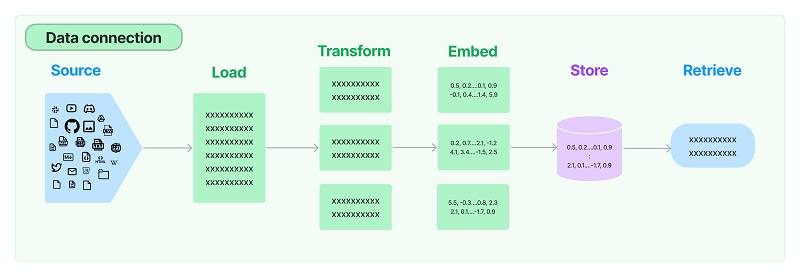
2.1 文档加载器:Document Loaders
1 | #!pip install pymupdf |
1 | from langchain_community.document_loaders import PyMuPDFLoader |
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron∗
Louis Martin†
Kevin Stone†
Peter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra
Prajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen
Guillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller
Cynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou
Hakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev
Punit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich
Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra
Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi
Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang
Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang
Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic
Sergey Edunov
Thomas Scialom∗
GenAI, Meta
Abstract
In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our
models outperform open-source chat models on most benchmarks we tested, and based on
our human evaluations for helpfulness and safety, may be a suitable substitute for closed-
source models. We provide a detailed description of our approach to fine-tuning and safety
improvements of Llama 2-Chat in order to enable the community to build on our work and
contribute to the responsible development of LLMs.
∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com
†Second author
Contributions for all the authors can be found in Section A.1.
arXiv:2307.09288v2 [cs.CL] 19 Jul 2023
2.2 文档处理器
2.2.1 TextSplitter
1 | #!pip install --upgrade langchain-text-splitters |
1 | from langchain_text_splitters import RecursiveCharacterTextSplitter |
Document Loaders 和 Text Splitters。2.3、向量数据库与向量检索
1 | from langchain_openai import OpenAIEmbeddings |
but are not releasing.§
- Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release
variants of this model with 7B, 13B, and 70B parameters as well.
We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs,
Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested,
Llama 2-Chat models generally perform better than existing open-source models. They also appear to
large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.
Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our
models outperform open-source chat models on most benchmarks we tested, and based on
更多的三方检索组件链接,参考:https://python.langchain.com/v0.2/docs/integrations/vectorstores/
2.4、小结
- 文档处理部分,建议在实际应用中详细测试后使用
- 与向量数据库的链接部分本质是接口封装,向量数据库需要自己选型
三、对话历史管理
3.1、历史记录的剪裁
1 | from langchain_core.messages import ( |
[AIMessage(content=”Hmmm let me think.\n\nWhy, he’s probably chasing after the last cup of coffee in the office!”, additional_kwargs={}, response_metadata={}),
HumanMessage(content=’what do you call a speechless parrot’, additional_kwargs={}, response_metadata={})]
1 | # 保留 system prompt |
[SystemMessage(content=”you’re a good assistant, you always respond with a joke.”, additional_kwargs={}, response_metadata={}),
HumanMessage(content=’what do you call a speechless parrot’, additional_kwargs={}, response_metadata={})]
3.2、过滤带标识的历史记录
1 | from langchain_core.messages import ( |
[HumanMessage(content=’example input’, additional_kwargs={}, response_metadata={}, name=’example_user’, id=’2’),
HumanMessage(content=’real input’, additional_kwargs={}, response_metadata={}, name=’bob’, id=’4’)]
1 | filter_messages(messages, exclude_names=["example_user", "example_assistant"]) |
[SystemMessage(content=’you are a good assistant’, additional_kwargs={}, response_metadata={}, id=’1’),
HumanMessage(content=’real input’, additional_kwargs={}, response_metadata={}, name=’bob’, id=’4’),
AIMessage(content=’real output’, additional_kwargs={}, response_metadata={}, name=’alice’, id=’5’)]
1 | filter_messages(messages, include_types=[HumanMessage, AIMessage], exclude_ids=["3"]) |
[HumanMessage(content=’example input’, additional_kwargs={}, response_metadata={}, name=’example_user’, id=’2’),
HumanMessage(content=’real input’, additional_kwargs={}, response_metadata={}, name=’bob’, id=’4’),
AIMessage(content=’real output’, additional_kwargs={}, response_metadata={}, name=’alice’, id=’5’)]
四、Chain 和 LangChain Expression Language (LCEL)
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的“提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
LCEL 的一些亮点包括:
- 流支持:使用 LCEL 构建 Chain 时,你可以获得最佳的首个令牌时间(即从输出开始到首批输出生成的时间)。对于某些 Chain,这意味着可以直接从 LLM 流式传输令牌到流输出解析器,从而以与 LLM 提供商输出原始令牌相同的速率获得解析后的、增量的输出。
- 异步支持:任何使用 LCEL 构建的链条都可以通过同步 API(例如,在 Jupyter 笔记本中进行原型设计时)和异步 API(例如,在 LangServe 服务器中)调用。这使得相同的代码可用于原型设计和生产环境,具有出色的性能,并能够在同一服务器中处理多个并发请求。
- 优化的并行执行:当你的 LCEL 链条有可以并行执行的步骤时(例如,从多个检索器中获取文档),我们会自动执行,无论是在同步还是异步接口中,以实现最小的延迟。
- 重试和回退:为 LCEL 链的任何部分配置重试和回退。这是使链在规模上更可靠的绝佳方式。目前我们正在添加重试/回退的流媒体支持,因此你可以在不增加任何延迟成本的情况下获得增加的可靠性。
- 访问中间结果:对于更复杂的链条,访问在最终输出产生之前的中间步骤的结果通常非常有用。这可以用于让最终用户知道正在发生一些事情,甚至仅用于调试链条。你可以流式传输中间结果,并且在每个 LangServe 服务器上都可用。
- 输入和输出模式:输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和 JSONSchema 模式。这可以用于输入和输出的验证,是 LangServe 的一个组成部分。
- 无缝 LangSmith 跟踪集成:随着链条变得越来越复杂,理解每一步发生了什么变得越来越重要。通过 LCEL,所有步骤都自动记录到 LangSmith,以实现最大的可观察性和可调试性。
- 无缝 LangServe 部署集成:任何使用 LCEL 创建的链都可以轻松地使用 LangServe 进行部署。
原文:https://python.langchain.com/docs/expression_language/
4.1 Pipeline 式调用 PromptTemplate, LLM 和 OutputParser
1 | from langchain_openai import ChatOpenAI |
1 | # 输出结构 |
{
“name”: null,
“price_lower”: null,
“price_upper”: 100,
“data_lower”: null,
“data_upper”: null,
“sort_by”: “data”,
“ordering”: “descend”
}
流式输出
1 | prompt = PromptTemplate.from_template("讲个关于{topic}的笑话") |
小明有一天上课迟到了,老师问他:“小明,你为什么迟到?”
小明回答:“老师,我在和时间赛跑。”
老师好奇地问:“那你怎么没赢呢?”
小明无奈地说:“因为时间用的是4G,我用的是2G。”
官方从不同角度给出了举例说明:https://python.langchain.com/v0.1/docs/expression_language/why/
4.2 用 LCEL 实现 RAG
1 | from langchain_openai import OpenAIEmbeddings |
1 | from langchain.schema.output_parser import StrOutputParser |
‘Llama 2有7B、13B和70B参数的变体。’
4.3 用 LCEL 实现工厂模式(选)
1 | from langchain_core.runnables.utils import ConfigurableField |
您好,我是文心一言,英文名是ERNIE Bot。我能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。
扩展阅读:什么是工厂模式;设计模式概览。
4.4 存储与管理对话历史
1 | from langchain_community.chat_message_histories import SQLChatMessageHistory |
1 | from langchain_core.messages import HumanMessage |
‘你好,王卓然!很高兴认识你。请问有什么我可以帮助你的吗?’
1 | runnable_with_history.invoke( |
‘是的,你叫王卓然。有什么我可以帮助你的吗?’
1 | runnable_with_history.invoke( |
‘抱歉,我不知道你的名字。如果你愿意,可以告诉我你的名字!’
通过 LCEL,还可以实现
- 配置运行时变量:https://python.langchain.com/v0.2/docs/how_to/configure/
- 故障回退:https://python.langchain.com/v0.2/docs/how_to/fallbacks
- 并行调用:https://python.langchain.com/v0.2/docs/how_to/parallel/
- 逻辑分支:https://python.langchain.com/v0.2/docs/how_to/routing/
- 动态创建 Chain: https://python.langchain.com/v0.2/docs/how_to/dynamic_chain/
更多例子:https://python.langchain.com/v0.2/docs/how_to/lcel_cheatsheet/
五、智能体架构:Agent
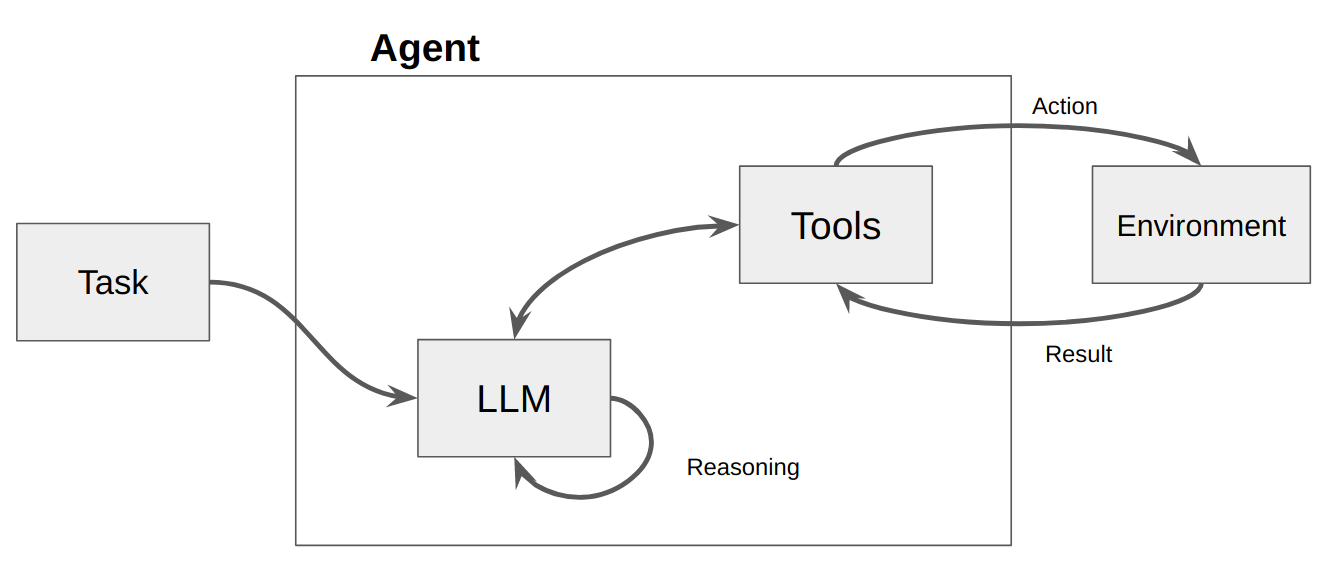
5.1 什么是智能体(Agent)
将大语言模型作为一个推理引擎。给定一个任务,智能体自动生成完成任务所需的步骤,执行相应动作(例如选择并调用工具),直到任务完成。
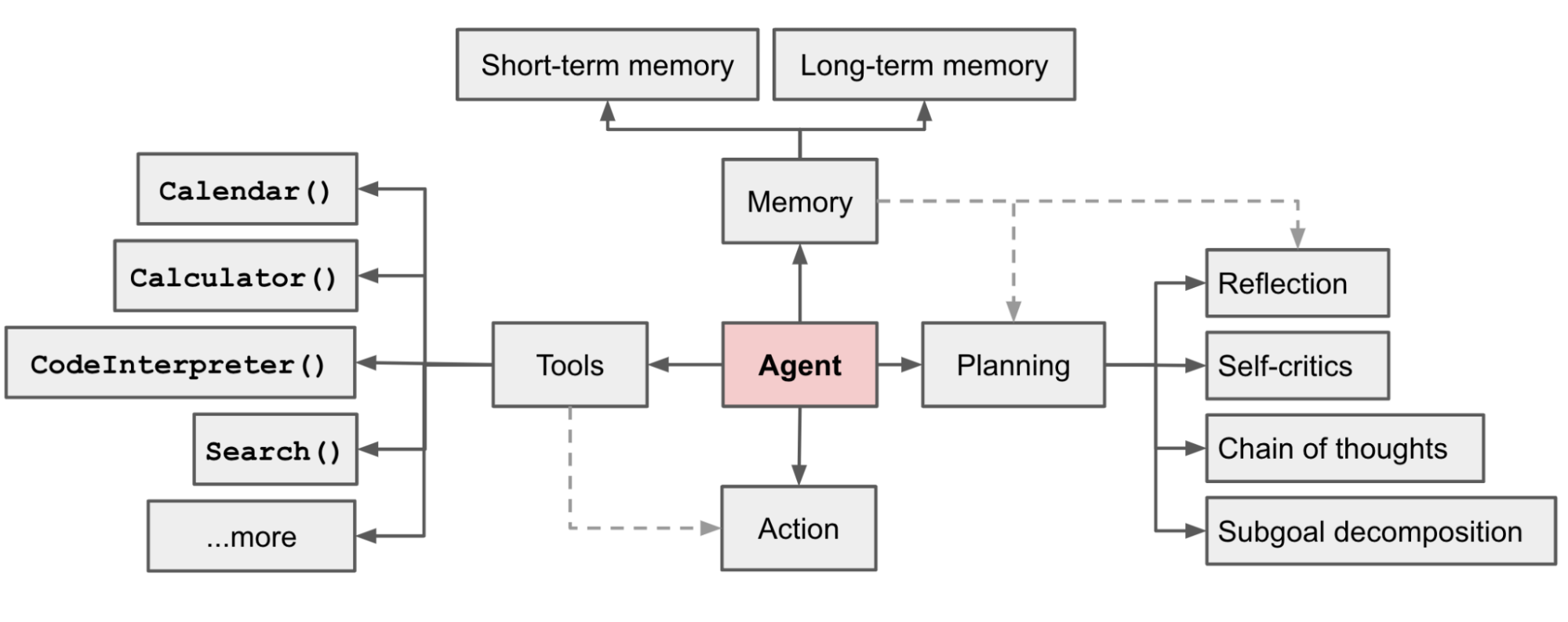
5.2 先定义一些工具:Tools
- 可以是一个函数或三方 API
- 也可以把一个 Chain 或者 Agent 的 run()作为一个 Tool
1 | from langchain_community.utilities import SerpAPIWrapper |
需要注册 SerpAPI(限量免费),并将 SERPAPI_API_KEY 写在环境变量中
1 | import calendar |
5.3 智能体类型:ReAct
1 | # !pip install google-search-results |
1 | # !pip install --upgrade langchainhub |
1 | from langchain import hub |
1 | from langchain_openai import ChatOpenAI |
5.4 智能体类型:SelfAskWithSearch
只用一个tool
1 | # 下载一个模板 |
1 | from langchain.agents import create_self_ask_with_search_agent |
六、LangServe
LangServe 用于将 Chain 或者 Runnable 部署成一个 REST API 服务。
1 | # 安装 LangServe |
6.1、Server 端
1 | #!/usr/bin/env python |
6.2、Client 端
1 | import requests |
七、LangChain.js
Python 版 LangChain 的姊妹项目,都是由 Harrison Chase 主理。
项目地址:https://github.com/langchain-ai/langchainjs
文档地址:https://js.langchain.com/docs/
特色:
- 可以和 Python 版 LangChain 无缝对接
- 抽象设计完全相同,概念一一对应
- 所有对象序列化后都能跨语言使用,但 API 差别挺大,不过在努力对齐
支持环境:
- Node.js (ESM and CommonJS) - 18.x, 19.x, 20.x
- Cloudflare Workers
- Vercel / Next.js (Browser, Serverless and Edge functions)
- Supabase Edge Functions
- Browser
- Deno
安装:
1 | npm install langchain |
当前重点:
- 追上 Python 版的能力(甚至为此做了一个基于 gpt-3.5-turbo 的代码翻译器)
- 保持兼容尽可能多的环境
- 对质量关注不多,随时间自然能解决
LangChain 与 LlamaIndex 的错位竞争
- LangChain 侧重与 LLM 本身交互的封装
- Prompt、LLM、Message、OutputParser 等工具丰富
- 在数据处理和 RAG 方面提供的工具相对粗糙
- 主打 LCEL 流程封装
- 配套 Agent、LangGraph 等智能体与工作流工具
- 另有 LangServe 部署工具和 LangSmith 监控调试工具
- LlamaIndex 侧重与数据交互的封装
- 数据加载、切割、索引、检索、排序等相关工具丰富
- Prompt、LLM 等底层封装相对单薄
- 配套实现 RAG 相关工具
- 有 Agent 相关工具,不突出
- LlamaIndex 为 LangChain 提供了集成
- 在 LlamaIndex 中调用 LangChain 封装的 LLM 接口:https://docs.llamaindex.ai/en/stable/api_reference/llms/langchain/
- 将 LlamaIndex 的 Query Engine 作为 LangChain Agent 的工具:https://docs.llamaindex.ai/en/v0.10.17/community/integrations/using_with_langchain.html
- LangChain 也 曾经 集成过 LlamaIndex,目前相关接口仍在:https://api.python.langchain.com/en/latest/retrievers/langchain_community.retrievers.llama_index.LlamaIndexRetriever.html
总结
- LangChain 随着版本迭代可用性有明显提升
- 使用 LangChain 要注意维护自己的 Prompt,尽量 Prompt 与代码逻辑解依赖
- 它的内置基础工具,建议充分测试效果后再决定是否使用
7、LangChain介绍





